
Introduction#
- Create VPC and 2 public and 2 private subnets
- Create a RDS PostgreSQL instance
- Create a EC2 webserver on public subnet
- Add security group and NACL on DB
- Develop simple go app
[!NOTE]
GitHub
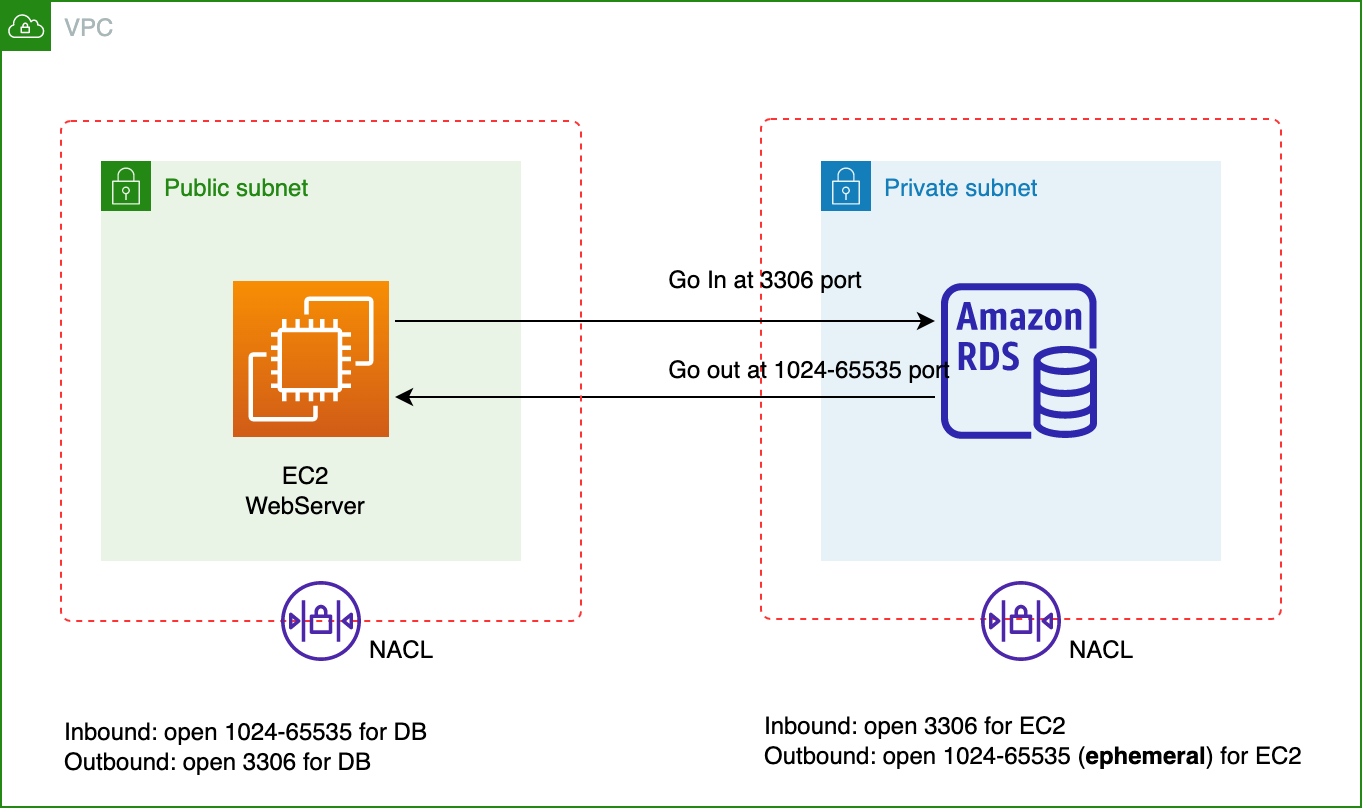
NACL Example 1#
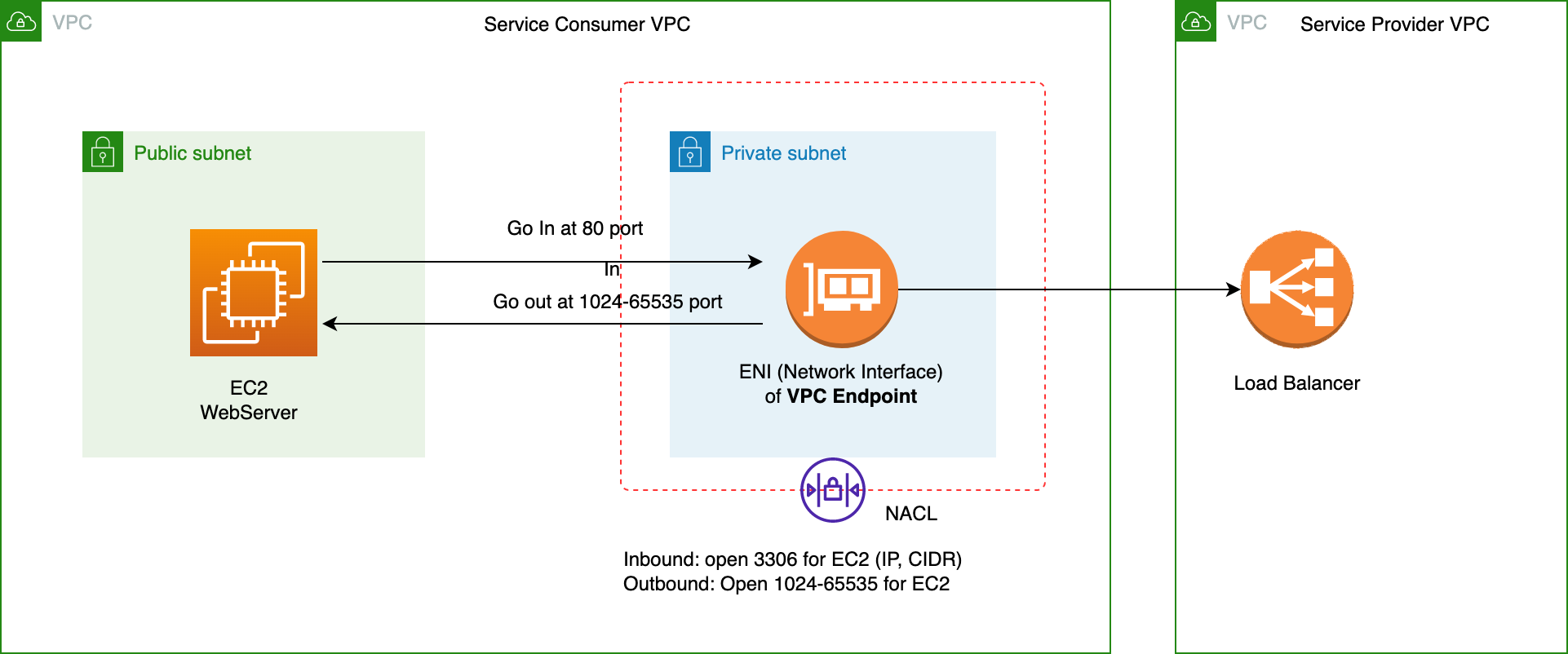
NACL Example 2#
Setup PostgreSQL#
Install psql client
sudo dnf install postgresql15.x86_64 postgresql15-server
Connect to the PostgreSQL instance
psql -h $HOST -p 5432 -U postgresql -d demo
List database
\l
Use database
\c demo;
List table
\dt
Create a table
CREATE TABLE IF NOT EXISTS book (id serial PRIMARY KEY,author TEXT,title TEXT,amazon TEXT,image TEXT);
Insert to a table
INSERT INTO book (author, title, amazon, image)values ('Hai Tran', 'Deep Learning', '', 'dog.jpg') RETURNING id;
Go Application#
- Static book page
- PostgreSQL page
project structure
|--static|book-template.html|--index.html|--main.go|--simple.go
This is webserver
main.go
package mainimport ("bytes""context""encoding/json""fmt""io""log""net/http""os""text/template""time""github.com/aws/aws-sdk-go-v2/aws""github.com/aws/aws-sdk-go-v2/config""github.com/aws/aws-sdk-go-v2/service/bedrockruntime""github.com/aws/aws-sdk-go-v2/service/bedrockruntime/types""gorm.io/driver/postgres""gorm.io/gorm""gorm.io/gorm/schema")// aws rds// const HOST = "database-1.c9y4mg20eppz.ap-southeast-1.rds.amazonaws.com"// const USER = "postgresql"// const PASS = "Admin2024"// const DBNAME = "demo"// local dbconst HOST = "localhost"const USER = "postgres"const DBNAME = "dvdrental"const PASS = "Mike@865525"type Book struct {ID uintTitle stringAuthor stringAmazon stringImage stringDescription string}func main() {// db initdns := fmt.Sprintf("host=%v port=%v user=%v password=%v dbname=%v", HOST, "5432", USER, PASS, DBNAME)db, _ := gorm.Open(postgres.Open(dns), &gorm.Config{NamingStrategy: schema.NamingStrategy{NoLowerCase: false,SingularTable: true,},})mux := http.NewServeMux()// home pagemux.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {http.ServeFile(w, r, "./static/bedrock.html")})// book pagemux.HandleFunc("/book", func(w http.ResponseWriter, r *http.Request) {http.ServeFile(w, r, "./static/book.html")})mux.HandleFunc("/postgresql", func(w http.ResponseWriter, r *http.Request) {// query a list of book []Bookbooks := getBooks(db)// load templatetmpl, error := template.ParseFiles("./static/book-template.html")if error != nil {fmt.Println(error)}// pass data to template and write to writertmpl.Execute(w, books)})// upload pagemux.HandleFunc("/upload", func(w http.ResponseWriter, r *http.Request) {switch r.Method {case "GET":http.ServeFile(w, r, "./static/upload.html")case "POST":uploadFile(w, r, db)}})// bedrock pagemux.HandleFunc("/bedrock-stream", bedrock)// create web serverserver := &http.Server{Addr: ":3000",Handler: mux,ReadTimeout: 30 * time.Second,WriteTimeout: 30 * time.Second,MaxHeaderBytes: 1 << 20,}// static filesmux.Handle("/demo/", http.StripPrefix("/demo/", http.FileServer(http.Dir("./static"))))// enable logginglog.Fatal(server.ListenAndServe())}func getBooks(db *gorm.DB) []Book {var books []Bookdb.Limit(10).Find(&books)for _, book := range books {fmt.Println(book.Title)}return books}func uploadFile(w http.ResponseWriter, r *http.Request, db *gorm.DB) {// maximum upload file of 10 MB filesr.ParseMultipartForm(10 << 20)// Get handler for filename, size and heandersfile, handler, error := r.FormFile("myFile")if error != nil {fmt.Println("Error")fmt.Println(error)return}defer file.Close()fmt.Printf("upload file %v\n", handler.Filename)fmt.Printf("file size %v\n", handler.Size)fmt.Printf("MIME header %v\n", handler.Header)// upload file to s3// _, error = s3Client.PutObject(context.TODO(), &s3.PutObjectInput{// Bucket: aws.String("cdk-entest-videos"),// Key: aws.String("golang/" + handler.Filename),// Body: file,// })// if error != nil {// fmt.Println("error upload s3")// }// Create filedest, error := os.Create("./static/" + handler.Filename)if error != nil {return}defer dest.Close()// Copy uploaded file to destif _, err := io.Copy(dest, file); err != nil {http.Error(w, err.Error(), http.StatusInternalServerError)return}// create a record in databasedb.Create(&Book{Title: "Database Internals",Author: "Hai Tran",Description: "Hello",Image: handler.Filename,})fmt.Fprintf(w, "Successfully Uploaded File\n")}// promt formatconst claudePromptFormat = "\n\nHuman: %s\n\nAssistant:"// bedrock runtime clientvar brc *bedrockruntime.Client// init bedorck credentials connecting to awsfunc init() {region := os.Getenv("AWS_REGION")if region == "" {region = "us-east-1"}cfg, err := config.LoadDefaultConfig(context.Background(), config.WithRegion(region))if err != nil {log.Fatal(err)}brc = bedrockruntime.NewFromConfig(cfg)}// bedrock handler requestfunc bedrock(w http.ResponseWriter, r *http.Request) {var query Queryvar message string// parse mesage from requesterror := json.NewDecoder(r.Body).Decode(&query)if error != nil {message = "how to learn japanese as quick as possible?"panic(error)}message = query.Topicfmt.Println(message)prompt := "" + fmt.Sprintf(claudePromptFormat, message)payload := Request{Prompt: prompt,MaxTokensToSample: 2048,}payloadBytes, error := json.Marshal(payload)if error != nil {fmt.Fprintf(w, "ERROR")// return "", error}output, error := brc.InvokeModelWithResponseStream(context.Background(),&bedrockruntime.InvokeModelWithResponseStreamInput{Body: payloadBytes,ModelId: aws.String("anthropic.claude-v2"),ContentType: aws.String("application/json"),},)if error != nil {fmt.Fprintf(w, "ERROR")// return "", error}for event := range output.GetStream().Events() {switch v := event.(type) {case *types.ResponseStreamMemberChunk://fmt.Println("payload", string(v.Value.Bytes))var resp Responseerr := json.NewDecoder(bytes.NewReader(v.Value.Bytes)).Decode(&resp)if err != nil {fmt.Fprintf(w, "ERROR")// return "", err}fmt.Println(resp.Completion)fmt.Fprintf(w, resp.Completion)if f, ok := w.(http.Flusher); ok {f.Flush()} else {fmt.Println("Damn, no flush")}case *types.UnknownUnionMember:fmt.Println("unknown tag:", v.Tag)default:fmt.Println("union is nil or unknown type")}}}type Request struct {Prompt string `json:"prompt"`MaxTokensToSample int `json:"max_tokens_to_sample"`Temperature float64 `json:"temperature,omitempty"`TopP float64 `json:"top_p,omitempty"`TopK int `json:"top_k,omitempty"`StopSequences []string `json:"stop_sequences,omitempty"`}type Response struct {Completion string `json:"completion"`}type HelloHandler struct{}type Query struct {Topic string `json:"topic"`}
The static book page
index.html
<!DOCTYPE html><!-- entest 29 april 2023 basic tailwind --><html><head><meta charset="UTF-8" /><meta name="viewport" content="width=device-width, initial-scale=1.0" /><linkhref="https://d2cvlmmg8c0xrp.cloudfront.net/web-css/review-book.css"rel="stylesheet"/></head><body class="bg-gray-100"><div class="bg-green-400 py-3"><nav class="flex mx-auto max-w-5xl justify-between"><a href="#" class="font-bold text-2xl"> Entest </a><ul class="hidden md:flex gap-x-3"><liclass="bg-white hover:bg-green-600 hover:text-white px-3 py-1 rounded-sm"><a href="https://cdk.entest.io/" target="_blank">About Me</a></li></ul></nav></div><divclass="bg-[url('https://d2cvlmmg8c0xrp.cloudfront.net/web-css/singapore.jpg')] bg-no-repeat bg-cover"><div class="mx-auto max-w-5xl pt-20 pb-48 pr-48 mb-10 text-right"><h2 class="invisible md:visible text-3xl font-bold mb-8">Good Books about AWS Cloud Computing</h2></div></div><div class="mx-auto max-w-5xl"><div class="md:flex gap-x-5 flex-row mb-8"><div class="ml-4 bg-white flex-auto w-full"><h4 class="font-bold mb-8">Data Engineering with AWS</h4><div><imgsrc="https://d2cvlmmg8c0xrp.cloudfront.net/web-css/data_engineering_with_aws.jpg"class="float-left h-auto w-64 mr-6"alt="book-image"/></div><p>This is a great book for understanding and implementing the lakehouse architecture to integrate your Data Lake with your warehouse.It shows you all the steps you need to orchestrate your datapipeline. From architecture, ingestion, and processing to runningqueries in your data warehouse, I really like the very hands-onapproach that shows you how you can immediately implement the topicsin your AWS account Andreas Kretz, CEO, Learn Data Engineering</p><ahref="https://www.amazon.com/Data-Engineering-AWS-Gareth-Eagar/dp/1800560419/ref=sr_1_1?crid=28BFB3NXGTM9G&keywords=data+engineering+with+aws&qid=1682772617&sprefix=data+engineering+with+aws%2Caps%2C485&sr=8-1"target="_blank"><buttonclass="bg-orange-300 px-14 py-3 rounded-md shadow-md hover:bg-orange-400">Amazon</button></a></div><div class="ml-4 bg-white flex-auto w-full"><h4 class="font-bold mb-8">Data Science on AWS</h4><div><imgsrc="https://d2cvlmmg8c0xrp.cloudfront.net/web-css/data_science_on_aws.jpg"class="float-left h-auto w-64 mr-6"alt="book-image"/></div><p></p><p>With this practical book, AI and machine learning practitioners willlearn how to successfully build and deploy data science projects onAmazon Web Services. The Amazon AI and machine learning stackunifies data science, data engineering, and application developmentto help level up your skills. This guide shows you how to build andrun pipelines in the cloud, then integrate the results intoapplications in minutes instead of days. Throughout the book,authors Chris Fregly and Antje Barth demonstrate how to reduce costand improve performance.</p><ahref="https://www.amazon.com/Data-Science-AWS-End-End/dp/1492079391/ref=sr_1_1?crid=17XK1VLHDZH59&keywords=data+science+on+aws&qid=1682772629&sprefix=data+science+on+%2Caps%2C327&sr=8-1"target="_blank"><buttonclass="bg-orange-300 px-14 py-3 rounded-md shadow-md hover:bg-orange-400">Amazon</button></a></div></div><div class="md:flex gap-x-5 flex-row mb-8"><div class="ml-4 bg-white flex-auto w-full"><h4 class="font-bold mb-8">Serverless Analytics with Amazon Athena</h4><div><imgsrc="https://d2cvlmmg8c0xrp.cloudfront.net/web-css/serverless_athena.jpg"class="float-left h-auto w-64 mr-6"alt="book-image"/></div><p>This book begins with an overview of the serverless analyticsexperience offered by Athena and teaches you how to build and tunean S3 Data Lake using Athena, including how to structure your tablesusing open-source file formats like Parquet. You willl learn how tobuild, secure, and connect to a data lake with Athena and LakeFormation. Next, you will cover key tasks such as ad hoc dataanalysis, working with ETL pipelines, monitoring and alerting KPIbreaches using CloudWatch Metrics, running customizable connectorswith AWS Lambda, and more. Moving on, you will work through easyintegrations, troubleshooting and tuning common Athena issues, andthe most common reasons for query failure.You will also review tipsto help diagnose and correct failing queries in your pursuit ofoperational excellence.Finally, you will explore advanced conceptssuch as Athena Query Federation and Athena ML to generate powerfulinsights without needing to touch a single server.</p><ahref="https://www.amazon.com/Serverless-Analytics-Amazon-Athena-semi-structured/dp/1800562349/ref=sr_1_1?crid=2KSTZBI4HUBZS&keywords=serverless+athena&qid=1682772648&sprefix=serverless+athe%2Caps%2C323&sr=8-1"target="_blank"><buttonclass="bg-orange-300 px-14 py-3 rounded-md shadow-md hover:bg-orange-400">Amazon</button></a></div><div class="ml-4 bg-white flex-auto w-full"><h4 class="font-bold mb-8">Serverless ETL and Analytics with AWS Glue</h4><div><imgsrc="https://d2cvlmmg8c0xrp.cloudfront.net/web-css/serverless_glue.jpg"class="float-left h-auto w-64 mr-6"alt="book-image"/></div><p></p><p>Beginning with AWS Glue basics, this book teaches you how to performvarious aspects of data analysis such as ad hoc queries, datavisualization, and real time analysis using this service. It alsoprovides a walk-through of CI/CD for AWS Glue and how to shift lefton quality using automated regression tests. You will find out howdata security aspects such as access control, encryption, auditing,and networking are implemented, as well as getting to grips withuseful techniques such as picking the right file format,compression, partitioning, and bucketing.As you advance, you willdiscover AWS Glue features such as crawlers, Lake Formation,governed tables, lineage, DataBrew, Glue Studio, and customconnectors. The concluding chapters help you to understand variousperformance tuning, troubleshooting, and monitoring options.</p><ahref="https://www.amazon.com/Serverless-ETL-Analytics-Glue-comprehensive/dp/1800564988/ref=sr_1_1?crid=HJXN5QBY7F2P&keywords=serverless+ETL+with+glue+aws&qid=1682772669&sprefix=serverless+etl+with+glue+a%2Caps%2C324&sr=8-1"target="_blank"><buttonclass="bg-orange-300 px-14 py-3 rounded-md shadow-md hover:bg-orange-400">Amazon</button></a></div></div><div class="md:flex gap-x-5 flex-row mb-8"><div class="ml-4 bg-white flex-auto w-full"><h4 class="font-bold mb-8">Simplify Big Data Analytics with Amazon EMR</h4><div><imgsrc="https://d2cvlmmg8c0xrp.cloudfront.net/web-css/amazon_emr.jpg"class="float-left h-auto w-64 mr-6"alt="book-image"/></div><p>Amazon EMR, formerly Amazon Elastic MapReduce, provides a managedHadoop cluster in Amazon Web Services (AWS) that you can use toimplement batch or streaming data pipelines. By gaining expertise inAmazon EMR, you can design and implement data analytics pipelineswith persistent or transient EMR clusters in AWS.This book is apractical guide to Amazon EMR for building data pipelines. You willstart by understanding the Amazon EMR architecture, cluster nodes,features, and deployment options, along with their pricing. Next,the book covers the various big data applications that EMR supports.You will then focus on the advanced configuration of EMRapplications, hardware, networking, security, troubleshooting,logging, and the different SDKs and APIs it provides. Later chapterswill show you how to implement common Amazon EMR use cases,including batch ETL with Spark, real time streaming with SparkStreaming, and handling UPSERT in S3 Data Lake with Apache Hudi.Finally, you will orchestrate your EMR jobs and strategize onpremises Hadoop cluster migration to EMR. In addition to this, youwill explore best practices and cost optimization techniques whileimplementing your data analytics pipeline in EMR</p><ahref="https://www.amazon.com/Simplify-Big-Data-Analytics-Amazon/dp/1801071071/ref=sr_1_1?crid=1BHYUKJ14LKNU&keywords=%22Simplify+Big+Data+Analytics+with+Amazon+EMR&qid=1682772695&sprefix=simplify+big+data+analytics+with+amazon+emr%2Caps%2C322&sr=8-1"target="_blank"><buttonclass="bg-orange-300 px-14 py-3 rounded-md shadow-md hover:bg-orange-400">Amazon</button></a></div><div class="ml-4 bg-white flex-auto w-full"><h4 class="font-bold mb-8">Scalable Data Streaming with Amazon Kinesis</h4><div><imgsrc="https://d2cvlmmg8c0xrp.cloudfront.net/web-css/amazon_kinesis.jpg"class="float-left h-auto w-64 mr-6"alt="book-image"/></div><p></p><p>Amazon Kinesis is a collection of secure, serverless, durable, andhighly available purpose built data streaming services. This datastreaming service provides APIs and client SDKs that enable you toproduce and consume data at scale. Scalable Data Streaming withAmazon Kinesis begins with a quick overview of the core concepts ofdata streams, along with the essentials of the AWS Kinesislandscape. You will then explore the requirements of the use caseshown through the book to help you get started and cover the keypain points encountered in the data stream life cycle. As youadvance, you will get to grips with the architectural components ofKinesis, understand how they are configured to build data pipelines,and delve into the applications that connect to them for consumptionand processing. You will also build a Kinesis data pipeline fromscratch and learn how to implement and apply practical solutions.Moving on, you will learn how to configure Kinesis on a cloudplatform. Finally, you will learn how other AWS services can beintegrated into Kinesis. These services include Redshift, DynamoDatabase, AWS S3, Elastic Search, and third-party applications suchas Splunk.</p><ahref="https://www.amazon.com/Scalable-Data-Streaming-Amazon-Kinesis/dp/1800565402/ref=sr_1_1?crid=1CC6W33MEW2GE&keywords=Scalable+Data+Streaming+with+Amazon+Kinesis&qid=1682772706&sprefix=scalable+data+streaming+with+amazon+kinesis%2Caps%2C312&sr=8-1"target="_blank"><buttonclass="bg-orange-300 px-14 py-3 rounded-md shadow-md hover:bg-orange-400">Amazon</button></a></div></div><div class="md:flex gap-x-5 flex-row mb-8"><div class="ml-4 bg-white flex-auto w-full"><h4 class="font-bold mb-8">Actionable Insights with Amazon QuickSight</h4><div><imgsrc="https://d2cvlmmg8c0xrp.cloudfront.net/web-css/amazon_quicksight.jpg"class="float-left h-auto w-64 mr-6"alt="book-image"/></div><p>Amazon Quicksight is an exciting new visualization that rivalsPowerBI and Tableau, bringing several exciting features to the tablebut sadly, there are not many resources out there that can help youlearn the ropes. This book seeks to remedy that with the help of anAWS certified expert who will help you leverage its fullcapabilities. After learning QuickSight is fundamental concepts andhow to configure data sources, you will be introduced to the mainanalysis-building functionality of QuickSight to develop visuals anddashboards, and explore how to develop and share interactivedashboards with parameters and on screen controls. You will diveinto advanced filtering options with URL actions before learning howto set up alerts and scheduled reports.</p><ahref="https://www.amazon.com/Actionable-Insights-Amazon-QuickSight-learning-driven/dp/1801079293/ref=sr_1_1?crid=1F6H7KDE97RHA&keywords=Actionable+Insights+with+Amazon+QuickSight&qid=1682772719&sprefix=actionable+insights+with+amazon+quicksight%2Caps%2C305&sr=8-1"target="_blank"><buttonclass="bg-orange-300 px-14 py-3 rounded-md shadow-md hover:bg-orange-400">Amazon</button></a></div><div class="ml-4 bg-white flex-auto w-full"><h4 class="font-bold mb-8">Amazon Redshift Cookbook</h4><div><imgsrc="https://d2cvlmmg8c0xrp.cloudfront.net/web-css/redshift_cook_book.jpg"class="float-left h-auto w-64 mr-6"alt="book-image"/></div><p></p><p>Amazon Redshift is a fully managed, petabyte-scale AWS cloud datawarehousing service. It enables you to build new data warehouseworkloads on AWS and migrate on-premises traditional datawarehousing platforms to Redshift. This book on Amazon Redshiftstarts by focusing on Redshift architecture, showing you how toperform database administration tasks on Redshift.You will thenlearn how to optimize your data warehouse to quickly execute complexanalytic queries against very large datasets. Because of the massiveamount of data involved in data warehousing, designing your databasefor analytical processing lets you take full advantage of Redshiftscolumnar architecture and managed services.As you advance, you willdiscover how to deploy fully automated and highly scalable extract,transform, and load (ETL) processes, which help minimize theoperational efforts that you have to invest in managing regular ETLpipelines and ensure the timely and accurate refreshing of your datawarehouse. Finally, you will gain a clear understanding of Redshiftuse cases, data ingestion, data management, security, and scaling sothat you can build a scalable data warehouse platform.</p><ahref="https://www.amazon.com/Amazon-Redshift-Cookbook-warehousing-solutions/dp/1800569688/ref=sr_1_1?crid=2P8V7A8548HBG&keywords=Amazon+Redshift+Cookbook&qid=1682772732&sprefix=amazon+redshift+cookbook%2Caps%2C315&sr=8-1&ufe=app_do%3Aamzn1.fos.006c50ae-5d4c-4777-9bc0-4513d670b6bc"target="_blank"><buttonclass="bg-orange-300 px-14 py-3 rounded-md shadow-md hover:bg-orange-400">Amazon</button></a></div></div><div class="md:flex gap-x-5 flex-row mb-8"><div class="ml-4 bg-white flex-auto w-full"><h4 class="font-bold mb-8">Automated Machine Learning on AWS</h4><div><imgsrc="https://d2cvlmmg8c0xrp.cloudfront.net/web-css/automated_ml_on_aws.jpg"class="float-left h-auto w-64 mr-6"alt="book-image"/></div><p>Automated Machine Learning on AWS begins with a quick overview ofwhat the machine learning pipeline/process looks like and highlightsthe typical challenges that you may face when building a pipeline.Throughout the book, you'll become well versed with various AWSsolutions such as Amazon SageMaker Autopilot, AutoGluon, and AWSStep Functions to automate an end-to-end ML process with the help ofhands-on examples. The book will show you how to build, monitor, andexecute a CI/CD pipeline for the ML process and how the variousCI/CD services within AWS can be applied to a use case with theCloud Development Kit (CDK). You'll understand what adata-centric ML process is by working with the Amazon ManagedServices for Apache Airflow and then build a managed Airflowenvironment. You'll also cover the key success criteria for anMLSDLC implementation and the process of creating a self-mutatingCI/CD pipeline using AWS CDK from the perspective of the platformengineering team</p><ahref="https://www.amazon.com/Automated-Machine-Learning-AWS-production-ready/dp/1801811822/ref=sr_1_1?crid=30X8QQER05M37&keywords=Automated+Machine+Learning+on+AWS&qid=1682772744&sprefix=automated+machine+learning+on+aws%2Caps%2C327&sr=8-1"target="_blank"><buttonclass="bg-orange-300 px-14 py-3 rounded-md shadow-md hover:bg-orange-400">Amazon</button></a></div><div class="ml-4 bg-white flex-auto w-full"><h4 class="font-bold mb-8">Kubernetes Up and Running</h4><div><imgsrc="https://d2cvlmmg8c0xrp.cloudfront.net/web-css/kubernetes_up_running.jpg"class="float-left h-auto w-64 mr-6"alt="book-image"/></div><p></p><p>In just five years, Kubernetes has radically changed the waydevelopers and ops personnel build, deploy, and maintainapplications in the cloud. With this book is updated third edition,you will learn how this popular container orchestrator can help yourcompany achieve new levels of velocity, agility, reliability, andefficiency whether you are new to distributed systems or have beendeploying cloud native apps for some time.</p><ahref="https://www.amazon.com/Kubernetes-Running-Dive-Future-Infrastructure/dp/109811020X/ref=sr_1_1?crid=2H4E57L24G3C5&keywords=Kubernetes+Up+and+Running&qid=1682772756&sprefix=kubernetes+up+and+running%2Caps%2C332&sr=8-1&ufe=app_do%3Aamzn1.fos.006c50ae-5d4c-4777-9bc0-4513d670b6bc"target="_blank"><buttonclass="bg-orange-300 px-14 py-3 rounded-md shadow-md hover:bg-orange-400">Amazon</button></a></div></div><div class="md:flex gap-x-5 flex-row mb-8"><div class="ml-4 bg-white flex-auto w-full"><h4 class="font-bold mb-8">Getting Started with Containerization</h4><div><imgsrc="https://d2cvlmmg8c0xrp.cloudfront.net/web-css/containerization.jpg"class="float-left h-auto w-64 mr-6"alt="book-image"/></div><p>Kubernetes is an open source orchestration platform for managingcontainers in a cluster environment. This Learning Path introducesyou to the world of containerization, in addition to providing youwith an overview of Docker fundamentals. As you progress, you willbe able to understand how Kubernetes works with containers. Startingwith creating Kubernetes clusters and running applications withproper authentication and authorization, you will learn how tocreate high- availability Kubernetes clusters on Amazon WebServices(AWS), and also learn how to use kubeconfig to managedifferent clusters.Whether it is learning about Docker containersand Docker Compose, or building a continuous delivery pipeline foryour application, this Learning Path will equip you with all theright tools and techniques to get started with containerization.</p><ahref="https://www.amazon.com/Getting-Started-Containerization-operational-automating-ebook/dp/B07Q4952SH/ref=sr_1_1?crid=3PUMFFKQW7EG6&keywords=getting+started+with+containerization&qid=1682772768&sprefix=getting+started+with+containerizatio%2Caps%2C318&sr=8-1"target="_blank"><buttonclass="bg-orange-300 px-14 py-3 rounded-md shadow-md hover:bg-orange-400">Amazon</button></a></div><div class="ml-4 bg-white flex-auto w-full"><h4 class="font-bold mb-8">Production Kubernetes</h4><div><imgsrc="https://d2cvlmmg8c0xrp.cloudfront.net/web-css/singapore.jpg"class="float-left h-auto w-64 mr-6"alt="book-image"/></div><p></p><p>Kubernetes has become the dominant container orchestrator, but manyorganizations that have recently adopted this system are stillstruggling to run actual production workloads. In this practicalbook, four software engineers from VMware bring their sharedexperiences running Kubernetes in production and provide insight onkey challenges and best practices. The brilliance of Kubernetes ishow configurable and extensible the system is, from pluggableruntimes to storage integrations. For platform engineers, softwaredevelopers, infosec, network engineers, storage engineers, andothers, this book examines how the path to success with Kubernetesinvolves a variety of technology, pattern, and abstractionconsiderations.</p><ahref="https://www.amazon.com/Production-Kubernetes-Successful-Application-Platforms/dp/B0C2JG8HN4/ref=sr_1_1?crid=2VL6HBN63YSKR&keywords=Production+Kubernetes&qid=1682772779&sprefix=production+kubernetes%2Caps%2C320&sr=8-1"target="_blank"><buttonclass="bg-orange-300 px-14 py-3 rounded-md shadow-md hover:bg-orange-400">Amazon</button></a></div></div><div class="md:flex gap-x-5 flex-row mb-8"><div class="ml-4 bg-white flex-auto w-full"><h4 class="font-bold mb-8">Practical Vim</h4><div><imgsrc="https://d2cvlmmg8c0xrp.cloudfront.net/web-css/practical_vim.jpg"class="float-left h-auto w-64 mr-6"alt="book-image"/></div><p>Vim is a fast and efficient text editor that will make you a fasterand more efficient developer. It's available on almost every OS,and if you master the techniques in this book, you will never needanother text editor. In more than 120 Vim tips, you will quicklylearn the editor's core functionality and tackle your trickiestediting and writing tasks. This beloved bestseller has been revisedand updated to Vim 8 and includes three brand-new tips and fivefully revised tips.</p><ahref="https://www.amazon.com/Practical-Vim-Edit-Speed-Thought/dp/1680501275/ref=sr_1_1?crid=37R58M1VK37ED&keywords=Practical+Vim&qid=1682772791&s=audible&sprefix=practical+vim%2Caudible%2C304&sr=1-1"target="_blank"><buttonclass="bg-orange-300 px-14 py-3 rounded-md shadow-md hover:bg-orange-400">Amazon</button></a></div><div class="ml-4 bg-white flex-auto w-full"><h4 class="font-bold mb-8">CSS In Depth</h4><div><imgsrc="https://d2cvlmmg8c0xrp.cloudfront.net/web-css/css_in_depth.jpeg"class="float-left h-auto w-64 mr-6"alt="book-image"/></div><p></p><p>CSS in Depth exposes you to a world of CSS techniques that rangefrom clever to mind-blowing. This instantly useful book is packedwith creative examples and powerful best practices that will sharpenyour technical skills and inspire your sense of design.</p><ahref="https://www.amazon.com/CSS-Depth-Keith-J-Grant/dp/1617293458/ref=sr_1_1?crid=SRUEMD3CZ94C&keywords=CSS+In+Depth&qid=1682772805&sprefix=css+in+depth%2Caps%2C326&sr=8-1"target="_blank"><buttonclass="bg-orange-300 px-14 py-3 rounded-md shadow-md hover:bg-orange-400">Amazon</button></a></div></div><div class="md:flex gap-x-5 flex-row mb-8"><div class="ml-4 bg-white flex-auto w-full"><h4 class="font-bold mb-8">Effective Typescript</h4><div><imgsrc="https://d2cvlmmg8c0xrp.cloudfront.net/web-css/effective_typescript.jpg"class="float-left h-auto w-64 mr-6"alt="book-image"/></div><p>TypeScript is a typed superset of JavaScript with the potential tosolve many of the headaches for which JavaScript is famous. ButTypeScript has a learning curve of its own, and understanding how touse it effectively can take time. This book guides you through 62specific ways to improve your use of TypeScript</p><ahref="https://www.amazon.com/Effective-TypeScript-Specific-Ways-Improve/dp/1492053740/ref=sr_1_1?crid=1BPGNPZ1QMNOI&keywords=%22Effective+Typescript&qid=1682772816&sprefix=effective+typescript%2Caps%2C318&sr=8-1"target="_blank"><buttonclass="bg-orange-300 px-14 py-3 rounded-md shadow-md hover:bg-orange-400">Amazon</button></a></div><div class="ml-4 bg-white flex-auto w-full"><h4 class="font-bold mb-8">Unix and Linux System Administration Handbook</h4><div><imgsrc="https://d2cvlmmg8c0xrp.cloudfront.net/web-css/unix_linux_admin.jpeg"class="float-left h-auto w-64 mr-6"alt="book-image"/></div><p></p><p>UNIX and Linux System Administration Handbook, Fifth Edition, istoday definitive guide to installing, configuring, and maintainingany UNIX or Linux system, including systems that supply coreInternet and cloud infrastructure. Updated for new distributions andcloud environments, this comprehensive guide covers best practicesfor every facet of system administration, including storagemanagement, network design and administration, security, webhosting, automation, configuration management, performance analysis,virtualization, DNS, security, and the management of IT serviceorganizations. The authors―world-class, hands-on technologists―offerindispensable new coverage of cloud platforms, the DevOpsphilosophy, continuous deployment, containerization, monitoring, andmany other essential topics.Whatever your role in running systemsand networks built on UNIX or Linux, this conversational,well-written ¿guide will improve your efficiency and help solve yourknottiest problems.</p><ahref="https://www.amazon.com/UNIX-Linux-System-Administration-Handbook/dp/0134277554/ref=sr_1_1?crid=1HWI8UE6KJ6PT&keywords=Unix+and+Linux+System+Administration+Handbook&qid=1682772831&sprefix=unix+and+linux+system+administration+handbook%2Caps%2C320&sr=8-1"target="_blank"><buttonclass="bg-orange-300 px-14 py-3 rounded-md shadow-md hover:bg-orange-400">Amazon</button></a></div></div><div class="md:flex gap-x-5 flex-row mb-8"><div class="ml-4 bg-white flex-auto w-full"><h4 class="font-bold mb-8">Computer Organization and Design</h4><div><imgsrc="https://d2cvlmmg8c0xrp.cloudfront.net/web-css/computer_organization.jpg"class="float-left h-auto w-64 mr-6"alt="book-image"/></div><p>Computer Organization and Design, Fifth Edition, is the latestupdate to the classic introduction to computer organization. Thetext now contains new examples and material highlighting theemergence of mobile computing and the cloud. It explores thisgenerational change with updated content featuring tablet computers,cloud infrastructure, and the ARM (mobile computing devices) and x86(cloud computing) architectures. The book uses a MIPS processor coreto present the fundamentals of hardware technologies, assemblylanguage, computer arithmetic, pipelining, memory hierarchies andI/Because an understanding of modern hardware is essential toachieving good performance and energy efficiency, this edition addsa new concrete example, Going Faster, used throughout the text todemonstrate extremely effective optimization techniques. There isalso a new discussion of the Eight Great Ideas of computerarchitecture. Parallelism is examined in depth with examples andcontent highlighting parallel hardware and software topics. The bookfeatures the Intel Core i7, ARM Cortex A8 and NVIDIA Fermi GPU asreal world examples, along with a full set of updated and improvedexercises.</p><ahref="https://www.amazon.com/Computer-Organization-Design-RISC-V-Architecture/dp/0128203315/ref=sr_1_1?crid=2SWQJ2EPAWKZT&keywords=Computer+Organization+and+Design&qid=1682772842&sprefix=computer+organization+and+design%2Caps%2C329&sr=8-1&ufe=app_do%3Aamzn1.fos.006c50ae-5d4c-4777-9bc0-4513d670b6bc"target="_blank"><buttonclass="bg-orange-300 px-14 py-3 rounded-md shadow-md hover:bg-orange-400">Amazon</button></a></div><div class="ml-4 bg-white flex-auto w-full"><h4 class="font-bold mb-8">Database Systems The Complete Book</h4><div><imgsrc="https://d2cvlmmg8c0xrp.cloudfront.net/web-css/database_system.jpg"class="float-left h-auto w-64 mr-6"alt="book-image"/></div><p></p><p>Database Systems: The Complete Book is ideal for Database Systemsand Database Design and Application courses offered at the junior,senior and graduate levels in Computer Science departments. A basicunderstanding of algebraic expressions and laws, logic, basic datastructure, OOP concepts, and programming environments is implied.Written by well-known computer scientists, this introduction todatabase systems offers a comprehensive approach, focusing ondatabase design, database use, and implementation of databaseapplications and database management systems.</p><ahref="https://www.amazon.com/Database-Systems-Complete-Book-2nd/dp/0131873253/ref=sr_1_1?crid=3E1GPJPYRNH9Z&keywords=Database+Systems+The+Complete+Book&qid=1682772851&sprefix=database+systems+the+complete+book%2Caps%2C336&sr=8-1&ufe=app_do%3Aamzn1.fos.f5122f16-c3e8-4386-bf32-63e904010ad0"target="_blank"><buttonclass="bg-orange-300 px-14 py-3 rounded-md shadow-md hover:bg-orange-400">Amazon</button></a></div></div></div><footer class="bg-gray-200 mt-12 text-gray-00 py-4"><div class="mx-auto max-w-5xl text-center text-base">Copyright © 2023 entest, Inc</div></footer></body></html>
The postgresql page
book-template.html
<html><head><style>.body {background-color: antiquewhite;}.container {max-width: 800px;margin-left: auto;margin-right: auto;}.title {font: bold;margin-bottom: 8px;}.image {float: left;height: auto;width: 128px;margin-right: 6px;}.card {margin-left: 4px;margin-right: 4px;background-color: white;width: 100%;}.grid {display: grid;row-gap: 10px;column-gap: 10px;grid-template-columns: repeat(1, minmax(0, 1fr));}@media (min-width: 35em) {.grid {grid-template-columns: repeat(2, minmax(0, 1fr));}}</style></head><body class="body"><div class="container"><div class="grid">{{range $book:= .}}<div class="card"><h4 class="title">{{ $book.Image}}</h4><h4 class="title">{{ $book.Author }}</h4><img src="/demo/{{ $book.Image }}" alt="book-image" class="image" /><p>Lorem ipsum dolor sit amet consectetur, adipisicing elit. Remquaerat quas corrupti cum blanditiis, sint non officiis minusmolestiae culpa consectetur ex voluptatibus distinctio ipsam.Possimus sint voluptatum at modi! Lorem ipsum, dolor sit ametconsectetur adipisicing elit. Alias dolore soluta error adipiscieius pariatur laborum sed impedit. Placeat minus aut perspiciatisdolor veniam, dolores odio sint eveniet? Numquam, tenetur! Loremipsum dolor sit amet consectetur adipisicing elit. Earum suscipitporro animi! Ducimus maiores et non. Minima nostrum ipsa voluptasassumenda consequuntur dicta reprehenderit numquam similique,nesciunt officiis facere optio. {{ $book.Description}}</p></div>{{end}}</div></div></body></html>
Most simple webserver which only serving a static page
package mainimport ("net/http""time")func main () {mux := http.NewServeMux()mux.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {// fmt.Fprintf(w, "Hello Minh Tran")http.ServeFile(w, r, "index.html")})server := &http.Server{Addr: ":3000",Handler: mux,ReadTimeout: 10 * time.Second,WriteTimeout: 10 * time.Second,MaxHeaderBytes: 1 << 20,}server.ListenAndServe()}
Basic Vimc#
This is a basic vimrc
" tab widthset tabstop=2set shiftwidth=2set softtabstop=2set expandtabset cindentset autoindentset smartindentset mouse=aset hlsearchset showcmdset titleset expandtabset incsearch" line numberset numberhi CursorLineNr cterm=None" highlight current lineset cursorlinehi CursorLine cterm=NONE ctermbg=23 guibg=Grey40" change cursor between modeslet &t_SI = "\e[6 q"let &t_EI = "\e[2 q"" netrw wsizelet g:netrw_liststyle=3let g:netrw_keepdir=0let g:netrw_winsize=30map <C-a> : Lexplore<CR>" per default, netrw leaves unmodified buffers open. This autocommand" deletes netrw's buffer once it's hidden (using ':q;, for example)autocmd FileType netrw setl bufhidden=delete " or use :qa!" these next three lines are for the fuzzy search:set nocompatible "Limit search to your projectset path+=** "Search all subdirectories and recursivelyset wildmenu "Shows multiple matches on one line" highlight syntaxset re=0syntax on" colorschemecolorscheme desert
Deploy#
- Using UserData
- User Docker
Here is UserData
#!/bin/bashcd /home/ec2-user/wget https://go.dev/dl/go1.21.5.linux-amd64.tar.gztar -xvf go1.21.5.linux-amd64.tar.gzecho 'export PATH=/home/ec2-user/go/bin:$PATH' >> ~/.bashrcwget https://github.com/cdk-entest/go-web-demo/archive/refs/heads/main.zipunzip maincd go-web-demo-main/~/go/bin/go mod tidy~/go/bin/go run main.go
Here is Dockerfile
# syntax=docker/dockerfile:1# Build the application from sourceFROM golang:1.21.5 AS build-stageWORKDIR /appCOPY go.mod go.sum ./RUN go mod downloadCOPY *.go ./RUN CGO_ENABLED=0 GOOS=linux go build -o /entest# Run the tests in the containerFROM build-stage AS run-test-stage# Deploy the application binary into a lean imageFROM gcr.io/distroless/base-debian11 AS build-release-stageWORKDIR /COPY --from=build-stage /entest /entestCOPY *.html ./COPY static ./staticEXPOSE 3000USER nonroot:nonrootENTRYPOINT ["/entest"]
And a buildscript in python
import os# parametersREGION = "us-east-1"ACCOUNT = os.environ["ACCOUNT_ID"]# delete all docker imagesos.system("sudo docker system prune -a")# build go-app imageos.system("sudo docker build -t go-app . ")# aws ecr loginos.system(f"aws ecr get-login-password --region {REGION} | sudo docker login --username AWS --password-stdin {ACCOUNT}.dkr.ecr.{REGION}.amazonaws.com")# get image idIMAGE_ID=os.popen("sudo docker images -q go-app:latest").read()# tag go-app imageos.system(f"sudo docker tag {IMAGE_ID.strip()} {ACCOUNT}.dkr.ecr.{REGION}.amazonaws.com/go-app:latest")# create ecr repositoryos.system(f"aws ecr create-repository --registry-id {ACCOUNT} --repository-name go-app")# push image to ecros.system(f"sudo docker push {ACCOUNT}.dkr.ecr.{REGION}.amazonaws.com/go-app:latest")# run locally to test# os.system(f"sudo docker run -d -p 3000:3000 go-app:latest")