
Introduction#
GitHub shows basic of model monitoring in SageMaker
- Data drift
- Model quality
- Bias drift
- Feature attribution drift
Data Drift#
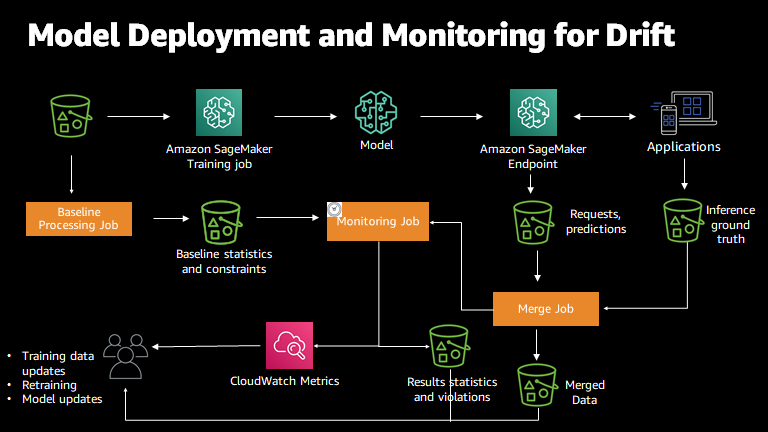
- Step 1) Enable data capture for the deployed endpoint
- Step 2) Generate baseline
- Step 3) Schedule and run the monitoring job
Step 1) Create and enable data capture in model deploy
from sagemaker.model_monitor import DataCaptureConfigdata_capture_config = DataCaptureConfig(enable_capture=True,sampling_percentage=100,destination_s3_uri=s3_capture_upload_path)
Deploy a model with data capture enabled
predictor = model.deploy(initial_instance_count=1,instance_type='ml.m4.xlarge',endpoint_name=endpoint_name,data_capture_config = data_capture_config)
Step 2) Generate baseline
This baseline job uses SageMaker Processing to analyze the training data at scale. For data drift, use DefaultModelMonitor to configure the infrastructure to execute the processing job on and the maxium run time.
from sagemaker.model_monitor import DefaultModelMonitorfrom sagemaker.model_monitor.dataset_format importDatasetFormatmy_default_monitor = DefaultModelMonitor(role=role,instance_count=1,instance_type="ml.m5.xlarge",volume_size_in_gb=20,max_runtime_in_seconds=3600,)
Use the suggest_baseline method on DefaultModelMonitor to configure and kick off the baseline job
my_default_monitor.suggest_baseline(baseline_dataset=baseline_data_uri + "/trainingdataset-with-header.csv",dataset_format=DatasetFormat.csv(header=True),output_s3_uri=baseline_results_uri,wait=True)
The baseline job results in two files statistic.json and constraints.json - saved in the s3 location you specifiec. The statistics.json file includes metadata analysis of the training data such as sum, mean, min, max values for numerical features and distinct counts for text features. The constraints.json file captures the threshold for the statistics for monitoring purpose.
Step 3) Schedule and execute data drift monitoring job
my_default_monitor.create_monitoring_schedule(monitor_schedule_name=mon_schedule_name,endpoint_input=predictor.endpoint,output_s3_uri=s3_report_path,statistics=my_default_monitor.baseline_statistics(),constraints=my_default_monitor.suggested_constraints(),schedule_cron_expression=CronExpressionGenerator.hourly(),enable_cloudwatch_metrics=True)
The job runs every hour using SageMaker Processing. The monitoring job compares the captured inference requests to the baseline. For each execution of the monitoring job, genenrated results include a violation report and a statistic erport saved in S3 and metrics emitted to CloudWatch.
Bias Drift#
- Step 1) Enable data captured for the endpoint
- Step 2) Generate baseline
- Step 3) Schedule and execute a model quality monitoring job
- Step 4) Anazlye and act on results
Step 1) Enable data captured for the endpoint
Step 2) Generate baseline
Create a baseline to measure the bias metrics of the training data. A bias drift baseline job needs mutiple inputs - the data to use for baseline, sensitive features, and facets to check for bias, a model to give predictions, and finally, a threshold value to indicate when a model prediction is biased.
Create a DataConfig
model_bias_data_config = DataConfig(s3_data_input_path=validation_dataset,s3_output_path=model_bias_baselining_job_result_uri,label=label_header,headers=all_headers,dataset_type='CSV')
Create BiasConfig
model_bias_config = BiasConfig(label_values_or_threshold=[1],facet_name="City",facet_values_or_threshold=[100],)
Create ModelConfig
model_config = ModelConfig(model_name=model_name,instance_count=endpoint_instance_count,instance_type=endpoint_instance_type,content_type=dataset_type,accept_type=dataset_type,)
Create ModelPredictedLabelConfig
model_predicted_label_config = ModelPredictedLabelConfig(probability_threshold=0.8,)
Create ModelBiasMonitor
model_bias_monitor = ModelBiasMonitor(role=role,sagemaker_session=sagemaker_session,max_runtime_in_seconds=1800,)
and
model_bias_monitor.suggest_baseline(model_config=model_config,data_config=model_bias_data_config,bias_config=model_bias_config,model_predicted_label_config=model_predicted_label_config,)
Step 3) Schedule and execute a model quality monitoring job
Step 4) Anazlye and act on results