
Introduction#
- Data Wrangler
- Basic Bias
- SageMaker Clarify
Wrangler Flow#
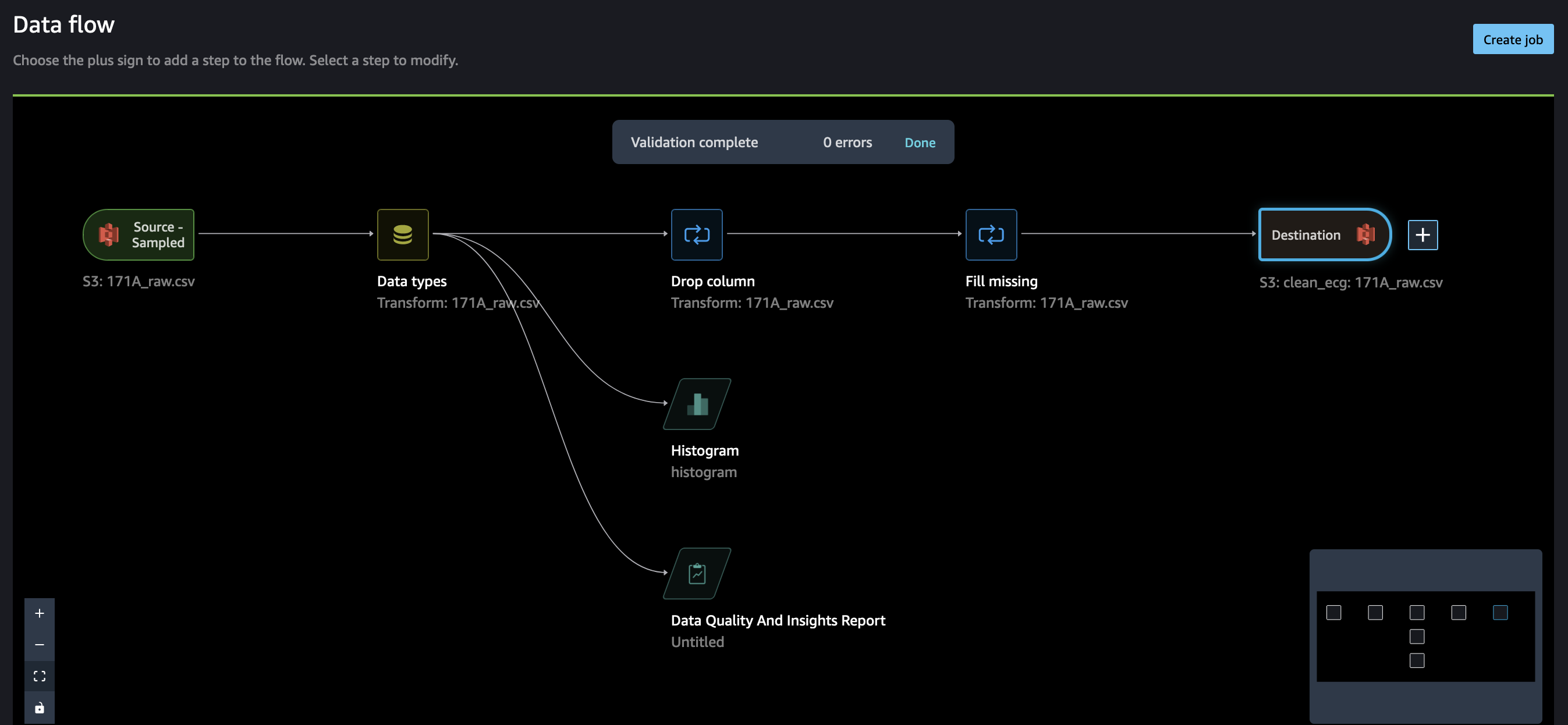
Let create a simple data flow with wrangler to
- check data quality
- drop some columns
- fill missing values
- add processing job
Upload the raw ecg data to s3
aws s3 cp 171A_raw.csv s3://bucket-name/ecg/
Import data to wrangler, and add analysis steps. Below is the entire flow
Data Bias Detection#
Some questions about Bias
- Does the group representation in the training data reflect the real world?
- Does the model have different accuracy for different groups?
Quoted what is bias mean: An imbalance in the training data or the prediction behavior of the model across different groups, such as age or income bracket. Biases can result from the data or algorithm used to train your model. For instance, if an ML model is trained primarily on data from middle-aged individuals, it may be less accurate when making predictions involving younger and older people. Sample Notebook and Blog
How to detecte bias
- Wrangler bias report
- Clarify for pre-training and post-training bias analysis
Let use SageMaker Clarify to detect bias in data. Download this bank additional dataset
wget https://sagemaker-sample-data-us-west-2.s3-us-west-2.amazonaws.com/autopilot/direct_marketing/bank-additional.zip
Then unzip and upload to S3
aws s3 cp . s3://bucket-name/bank-additional/ --recursive
Create a wrangler flow, import data, and add an analysis to see the Bias report.
- Predicted Y: term deposit
- Bias analysis on column: martial
The Bias report show some basic metrics such as Class Imbalance.
CI = (na - nd)(na + nd)
From the results, we observe a class imbalance where the married class is 21% more represented than other classes. We also observe that the married class is 2.8% less likely to subscribe to a bank term deposit.
SageMaker Clarify#
Follow this notebook to understand how to use SageMaker Clarify to detect bias pre-training and post-training.
Inspect male versus female representation in label
training_data["Sex"].value_counts().sort_values().plot(kind="bar", title="Counts of Sex", rot=0)
Inspect male versus female representation in possible label
training_data["Sex"].where(training_data["Target"] == ">50K").value_counts().sort_values().plot(kind="bar", title="Counts of Sex earning >$50K", rot=0)
Create SageMaker Clarify Processor
clarify_processor = clarify.SageMakerClarifyProcessor(role=role,instance_count=1,instance_type="ml.m5.xlarge",sagemaker_session=sagemaker_session)
Create Writing DataConfig which communicates some basic information about data I/O to SageMaker Clarify.
bias_report_output_path = "s3://{}/{}/clarify-bias".format(bucket, prefix)bias_data_config = clarify.DataConfig(s3_data_input_path=train_uri,s3_output_path=bias_report_output_path,label="Target",headers=training_data.columns.to_list(),dataset_type="text/csv",)
Create Writing ModelConfig which is an object communicates information about your trained model.
model_config = clarify.ModelConfig(model_name=model_name,instance_type="ml.m5.xlarge",instance_count=1,accept_type="text/csv",content_type="text/csv",)
Create Writing ModelPredictedLabelConfig provides information on the format of your predictions
predictions_config = clarify.ModelPredictedLabelConfig(probability_threshold=0.8)
Create Writing BiasConfig contains configuration values for detecting bias using a Clarify container.
bias_config = clarify.BiasConfig(label_values_or_threshold=[1],facet_name="Sex",facet_values_or_threshold=[0],group_name="Age")
Run the Clarify Processor to get bias information of post-training and pre-training
clarify_processor.run_bias(data_config=bias_data_config,bias_config=bias_config,model_config=model_config,model_predicted_label_config=predictions_config,pre_training_methods="all",post_training_methods="all",)
Finally, you can find the bias report in SageMaker Studio Experiments.