
Introduction#
Build a Basic ML Pipeline with SageMaker Pipeline and integrate with CodePipeline.
- Option 1. Create a ML pipeline by sagemaker pipeline
- Option 2. Create a ML pipeline by stepfunctions
Architecture

Option 1. SageMaker Pipeline#
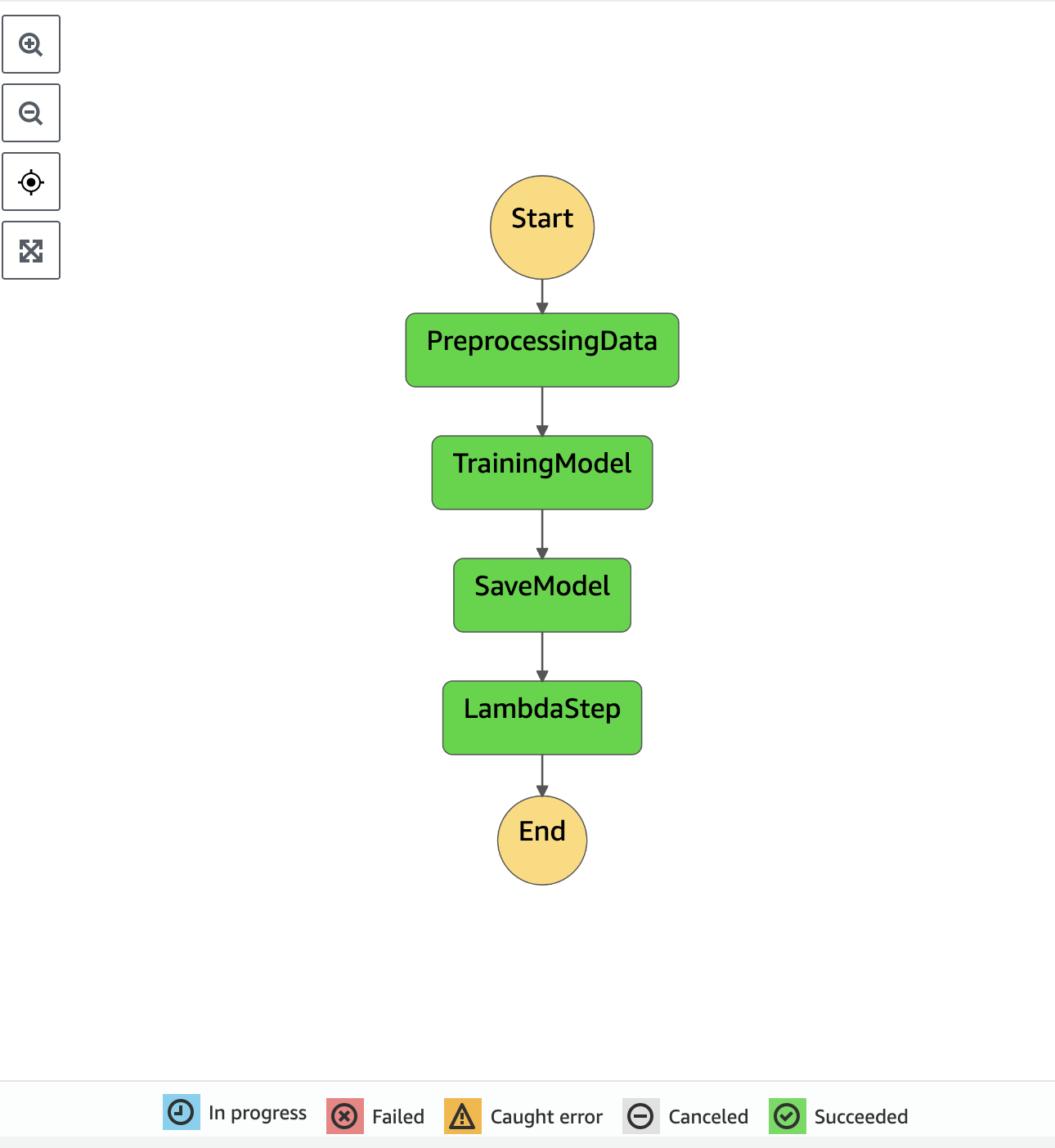
The sagemaker_pipeline.py creates a sagemaker pipeline. It consits of multiple steps/functions.
- create a processing step for preprocessing data. This process data and split into test, train, validation datasets and store in the default sagemaker S3 bucket.
def create_process_step() -> ProcessingStep:"""create process step for pre-processing data"""sklearn_processor = SKLearnProcessor(framework_version="0.23-1",instance_type="ml.m5.xlarge",instance_count=processing_instance_count,base_job_name="sklearn-abalone-process",role=role)step_process = ProcessingStep(name="AbaloneProcess",processor=sklearn_processor,inputs=[ProcessingInput(source=input_data_uri,destination="/opt/ml/processing/input"),],outputs=[ProcessingOutput(output_name="train",source="/opt/ml/processing/train",),ProcessingOutput(output_name="validation",source="/opt/ml/processing/validation"),ProcessingOutput(output_name="test",source="/opt/ml/processing/test")],code="preprocessing.py")return step_process
- create a training step. The container in this step will train a xgboost algorithm with test, train, validation datasets from the previous step. Then it will save model data to the defaul S3 bucket. Next step, we will build a model from the data model.
def create_training_step(s3_train_data, s3_validation_data):"""create a training step"""image_uri = sagemaker.estimator.image_uris.retrieve(framework="xgboost",region="ap-southeast-1",version="1.0-1",py_version="py3",instance_type="ml.m5.xlarge")xgb_train = Estimator(image_uri=image_uri,instance_type="ml.m5.xlarge",instance_count=training_instance_count,output_path=model_path,role=role)xgb_train.set_hyperparameters(objective="reg:linear",num_round=50,max_depth=5,eta=0.2,gamma=4,min_child_weight=6,subsample=0.7,silent=0)step_train = TrainingStep(name="AbaloneTrain",estimator=xgb_train,inputs={"train": TrainingInput(s3_data=s3_train_data,content_type="text/csv"),"validation": TrainingInput(s3_data=s3_validation_data,content_type="text/csv")})return step_train
- create a model step. This step will build a sagemaker model with the model data from the previous step, and ready for sagemaker endpoint deployment.
def create_model_batch(step_train: TrainingStep):"""create model for batch transform"""model = Model(image_uri=sagemaker.estimator.image_uris.retrieve(framework="xgboost",region="ap-southeast-1",version="1.0-1",py_version="py3",instance_type="ml.m5.xlarge"),model_data=step_train.properties.ModelArtifacts.S3ModelArtifacts,sagemaker_session=session,role=role)inputs = sagemaker.inputs.CreateModelInput(instance_type="ml.m5.large",accelerator_type="ml.eia1.medium")step_create_model = sagemaker.workflow.steps.CreateModelStep(name="AbaloneCreateModel",model=model,inputs=inputs)return step_create_model
- Create a lambda function to save modelName to parameter store.
export class LambdaRecordModelName extends Stack {public readonly lambadArn: stringconstructor(scope: Construct, id: string, props: StackProps) {super(scope, id, props)const func = new aws_lambda.Function(this, 'LambdaRecordModelName', {functionName: 'LambdaRecordModelName',code: aws_lambda.Code.fromInline(fs.readFileSync(path.join(__dirname, './../lambda/index.py'), {encoding: 'utf-8'})),runtime: aws_lambda.Runtime.PYTHON_3_8,handler: 'index.handler'})func.addToRolePolicy(new aws_iam.PolicyStatement({effect: Effect.ALLOW,actions: ['ssm:*'],resources: ['*']}))this.lambadArn = func.functionArn}}
the lambda handler to write the sagemaker model name into ssm
import jsonimport boto3def lambda_handler(event, context):# parse model namemodel_name=event['model_name']# ssm clientssm = boto3.client('ssm')# write model name to parameter storessm.put_parameter(Name="HelloModelNameSps",Value=model_name,Overwrite=True)return {'statusCode': 200,'body': json.dumps('Hello from Lambda!')}
- Integrate the lambda as a lambad step into the sagemaker pipeline.
def create_lambda_step(model_name: str) -> LambdaStep:"""create a lambda step"""lambda_step = LambdaStep(name="LambdaRecordModelNameToParameterStore",lambda_func=Lambda(function_arn=os.environ['LAMBDA_ARN'],session=session),inputs={"model_name": model_name})return lambda_step
- create a sagemaker pipeline. Finally, we chain processing step, train step, model step, and lambda step into a sagemaker pipeline or workflow. It is possible to use stepfunctions instead of sagemaker pipeline here.
def create_pipeline():"""create sagemaker pipeline"""# preprocessing stepprocessing_step = create_process_step()# training steptraining_step = create_training_step(s3_train_data=processing_step.properties.ProcessingOutputConfig.Outputs["train"].S3Output.S3Uri,s3_validation_data=processing_step.properties.ProcessingOutputConfig.Outputs["validation"].S3Output.S3Uri,)# create model for batch transformmodel_step = create_model_batch(step_train=training_step)# lambda steplambda_step = create_lambda_step(model_name=model_step.properties.ModelName)# sagemaker pipelineex_pipeline = Pipeline(name="AbalonePipelineTestPrintName",parameters=[processing_instance_count,training_instance_count,model_approval_status,input_data,batch_data],steps=[processing_step, training_step, model_step, lambda_step],sagemaker_session=session)return ex_pipeline
Option 2. Stepfunctions#
stepfunctions_pipeline.py implements a ML pipeline by using stepfunctions.
def create_workflow() -> stepfunctions.workflow.Workflow:"""create a state machine for ml pipeline"""# processing stepprocessing_step = create_process_step()# training steptraining_step = create_training_step()# create model stepmodel_step = create_model_batch(training_step=training_step)# lambda steplambda_step = create_lambda_step(model_name=execution_input["ModelName"])# workflowdefinition = stepfunctions.steps.Chain([processing_step, training_step, model_step, lambda_step])workflow = stepfunctions.workflow.Workflow(name="StepFunctionWorkFlow",definition=definition,role=config["WORKFLOW_ROLE"],execution_input=execution_input,)return workflow
Use ExecutionInput to dynamically pass jobName, ModelName
execution_input = ExecutionInput(schema={"PreprocessingJobName": str,"TrainingJobName": str,"LambdaFunctionName": str,"ModelName": str,})
Provide SAGEMAKER_ROLE and WORKFLOW_ROLE reference HERE
CodePipeline#
We now build a normal codepipeline with stages.
- Stage 1. A codebuild to run the python sagemaker_pipeline.py to create a sagemaker pipeline and the model also.
- Stage 2. A codebuild to build a template for deploying a sagemker endpoint
- Stage 3. A codedeploy to deploy (create or update) the template - sagemaker endpoint
- Missing stages:
- Evaluation model and condition
- Experiment and trial
- Sagemaker model monitoring
storing pipeline artifacts
// artifact storeconst sourceOutput = new aws_codepipeline.Artifact('SourceOutput')const cdkBuildOutput = new aws_codepipeline.Artifact('CdkBuildOutput')const sageMakerBuildOutput = new aws_codepipeline.Artifact('SageMakerBuildOutput')
source code from GitHub
new aws_codepipeline_actions.CodeStarConnectionsSourceAction({actionName: "Github",owner: "entest-hai",repo: "sagemaker-pipeline",branch: "stepfunctions",connectionArn: `arn:aws:codestar-connections:${this.region}:${this.account}:connection/${props.codeStartId}`,output: sourceOutput,}),
a codebuild project to create and run the sagemaker pipeline
const sageMakerBuild = new aws_codebuild.PipelineProject(this,'BuildSageMakerModel',{projectName: 'BuildSageMakerModel',environment: {privileged: true,buildImage: aws_codebuild.LinuxBuildImage.STANDARD_5_0,computeType: aws_codebuild.ComputeType.MEDIUM,environmentVariables: {SAGEMAKER_ROLE: {value: props.sageMakerRole},LAMBDA_ARN: {value: props.lambdaArn}}},buildSpec: aws_codebuild.BuildSpec.fromObject({version: '0.2',phases: {install: {commands: ['pip install -r requirements.txt']},build: {commands: ['python sagemaker_pipeline.py']}}})})
andd policy to allow the codebuild and run sagemaker
sageMakerBuild.addToRolePolicy(new aws_iam.PolicyStatement({effect: aws_iam.Effect.ALLOW,resources: ['*'],actions: ['sagemaker:*','s3:*','lambda:*','iam:GetRole','iam:PassRole','states:*','logs:*']}))
a codebuild project to build a template for deploying the sagemaker endpoint
const cdkBuildProject = new aws_codebuild.PipelineProject(this,'CdkBuildSageMakerEndpoint',{projectName: 'CdkBuildSageMakerEndpoint',environment: {privileged: true,buildImage: aws_codebuild.LinuxBuildImage.STANDARD_5_0,computeType: aws_codebuild.ComputeType.MEDIUM},buildSpec: aws_codebuild.BuildSpec.fromObject({version: '0.2',phases: {install: {commands: ['cd cdk-model-deploy', 'npm install']},build: {commands: ['npm run build', 'npm run cdk synth -- -o dist']}},artifacts: {'base-directory': 'cdk-model-deploy/dist',files: ['*.template.json']}})})
the entire codepipeline
// codepipelineconst pipeline = new aws_codepipeline.Pipeline(this,'CiCdPipelineForSageMaker',{pipelineName: 'CiCdPipelineForSageMaker',stages: [{stageName: 'SourceStage',actions: [new aws_codepipeline_actions.CodeStarConnectionsSourceAction({actionName: 'Github',owner: 'entest-hai',repo: 'sagemaker-pipeline',branch: 'stepfunctions',connectionArn: `arn:aws:codestar-connections:${this.region}:${this.account}:connection/${props.codeStartId}`,output: sourceOutput})]},{stageName: 'BuildCdkStage',actions: [new aws_codepipeline_actions.CodeBuildAction({actionName: 'BuildSagemakerEndpointStack',project: cdkBuildProject,input: sourceOutput,outputs: [cdkBuildOutput],runOrder: 1})]},{stageName: 'BuildSageMakerModel',actions: [new aws_codepipeline_actions.CodeBuildAction({actionName: 'BuildSageMakerModel',project: sageMakerBuild,input: sourceOutput,outputs: [sageMakerBuildOutput],runOrder: 1})]},{stageName: 'DeploySageMakerModel',actions: [new aws_codepipeline_actions.CloudFormationCreateUpdateStackAction({actionName: 'DeploySageMakerEndpoint',stackName: 'CdkModelDeployStack',templatePath: cdkBuildOutput.atPath('CdkModelDeployStack.template.json'),adminPermissions: true})]}]})
Deployment#
- Step 1. setup the SageMaker IAM role
- Step 2. upload the data to S3
- Step 3. update the condestar id
- Step 4. deploy the pipepline and skip the ModelDeployStack
- Step 5. uncomment the ModelDeployStack and git push
Step 1. Setup the IAM role for SageMaker. Below is the SageMakerRoleStack
// sagemakerthis.role.addManagedPolicy(aws_iam.ManagedPolicy.fromAwsManagedPolicyName('AmazonSageMakerFullAccess'))// cloudwatchthis.role.addManagedPolicy(aws_iam.ManagedPolicy.fromAwsManagedPolicyName('CloudWatchEventsFullAccess'))// stepfunctionthis.role.addManagedPolicy(aws_iam.ManagedPolicy.fromAwsManagedPolicyName('AWSStepFunctionsFullAccess'))// lambda to invoke lambda stackthis.role.addToPolicy(new aws_iam.PolicyStatement({effect: Effect.ALLOW,resources: ['*'],actions: ['lambda:InvokeFunction']}))// access data s3this.role.addToPolicy(new aws_iam.PolicyStatement({effect: Effect.ALLOW,resources: ['*'],actions: ['s3:*']}))
Step 2. Upload the data to S3
aws s3 cp data/ s3:://{BUCKET}/abalone/ --recursive
Step 3, 4, 5.
Next Steps#
- Try replacing sagemaker pipeline by stepfunctions to create the workflow
- Add sagemaker experiment and trials
- Add model registry
- Add model evaluation and condition before deploy
- Add manual approval and email notification
- Add sagemaker endpoint monitoring