
Introduction#
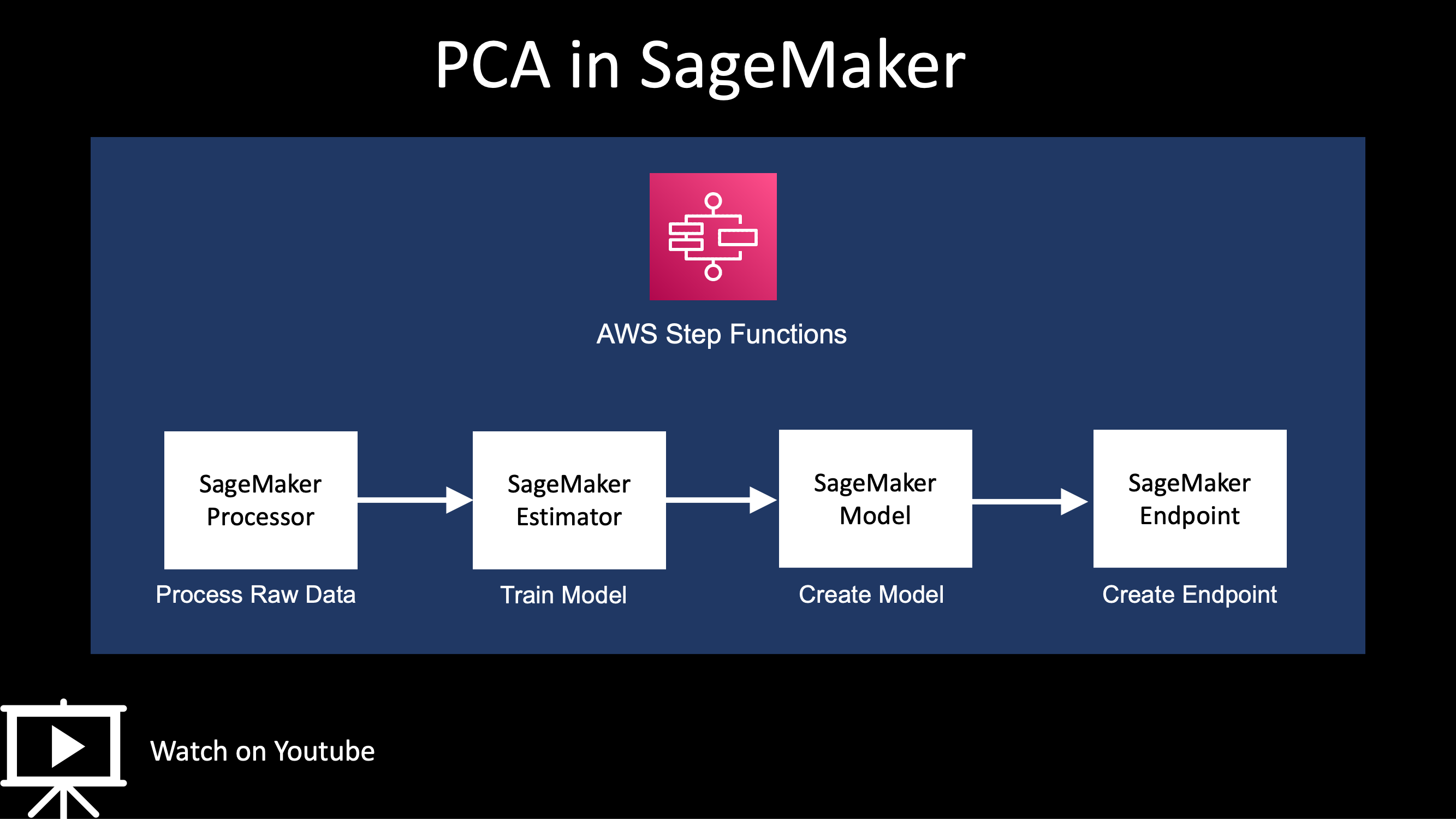
GitHub this builds a simple pipeline for PCA
- process raw data by processor and processing step
- train model by estimator and training step
- create a model by model step
- create an endpoint and invoke by boto3 or sagemaker predictor
Process Raw Data#
process raw data stored in S3 by using a SKLearnProcessor and wrap into a processing step of the stepfunctions. It is possible to set instance_count greater than 1 and data distributed into instances.
def create_processing_step() -> stepfunctions.steps.ProcessingStep:"""create processing step which process raw data"""processor = SKLearnProcessor(framework_version="0.23-1",instance_type="ml.m5.xlarge",instance_count=1,base_job_name="process-raw-data-01",role=os.environ["SAGEMAKER_ROLE"],)step_process = stepfunctions.steps.ProcessingStep(state_id="PreprocessingData",processor=processor,job_name=execution_input["PreprocessingJobName"],inputs=[ProcessingInput(input_name="train-data-input",source=input_data_uri,destination=f"{container_base_path}/data",),ProcessingInput(input_name="train-code-input",source=input_code_uri,destination=f"{container_base_path}/input",),],outputs=[ProcessingOutput(output_name="train",source=f"{container_base_path}/output",destination=processing_output_path,)],container_entrypoint=["python3",f"{container_base_path}/input/process_raw_data.py",],)return step_process
Train Model#
train the PCA estimator
def create_training_step() -> stepfunctions.steps.TrainingStep:"""create a training step"""# get sklearn image uriimage_uri = sagemaker.estimator.image_uris.retrieve(framework="pca",region=os.environ["REGION"],version="0.23-1",instance_type="ml.m4.xlarge",)# create an estimatorestimator = sagemaker.estimator.Estimator(image_uri=image_uri,instance_type="ml.m4.xlarge",instance_count=1,# output_path="",role=os.environ["SAGEMAKER_ROLE"],)# set hyperparameterestimator.set_hyperparameters(feature_dim=4, num_components=3, mini_batch_size=200)# create a train stepstep_train = stepfunctions.steps.TrainingStep(job_name=execution_input["TrainingJobName"],state_id="PCATrainingStep",estimator=estimator,data={"train": sagemaker.TrainingInput(content_type="text/csv;label_size=0",s3_data=f's3://{os.environ["SAGEMAKER_BUCKET"]}/pca-processed-data',)},)# returnreturn step_train
Create Model#
after training, we can create a model from the trained artifact stored in S3
def create_model_step(training_step: stepfunctions.steps.TrainingStep,) -> stepfunctions.steps.ModelStep:"""create a model step"""model_step = stepfunctions.steps.ModelStep(state_id="PcaModelStep",model=training_step.get_expected_model(),model_name=execution_input["ModelName"],)return model_step
Create a Pipeline#
This step uses stepfunctions to create a workflow
def create_workflow() -> stepfunctions.workflow.Workflow:"""create workflow by stepfunctions"""# processing stepprocessing_step = create_processing_step()# training steptraining_step = create_training_step()# model stepmodel_step = create_model_step(training_step)# workflowdefinition = stepfunctions.steps.Chain([processing_step, training_step, model_step])print(os.environ["SAGEMAKER_ROLE"])workflow = stepfunctions.workflow.Workflow(name="StepFunctionWorkFlowDemo001",definition=definition,role=os.environ["SAGEMAKER_ROLE"],execution_input=execution_input,)return workflow
Create Endpoint#
serve the model by creating an endpoint
def create_end_point(model_name, endpoint_name):"""create an endpoint"""# sagemaker clientsg = boto3.client("sagemaker")# create endpoint configurationendpoint_config_name = "PCAEndpointConfigName"#try:sg.create_endpoint_config(EndpointConfigName=endpoint_config_name,ProductionVariants=[{"VariantName": "test","ModelName": model_name,"InstanceType": "ml.m4.xlarge","InitialInstanceCount": 1,}],)except:print("configuration already existed")pass# create an endpointendpoint = sg.create_endpoint(EndpointName=endpoint_name,EndpointConfigName=endpoint_config_name,)return endpointgiven the deployed enpoint, we can invoke it by boto3 or sagemaker predictordef test_boto3_invoke_endpoint(endpoint_name):"""test the pca endpoint"""client = boto3.client("sagemaker-runtime")resp = client.invoke_endpoint(EndpointName=endpoint_name,ContentType="text/csv",Body="1,2,3,4",)print(json.loads(resp["Body"].read()))return resp
SageMaker Cli#
list endpoint
aws list-endpoints
delete an endpoint
aws delete-endpoint --endpoint-name $ENDPOINT_NAME
list endpoint configuration
aws list-endpoint-configs
delete endpoint configuration
aws delete-endpoint-config --endpoint-config-name $ENDPOINT_CONFIG_NAME
SageMaker Role#
To create a pipeline using stepfunction, role for this script needs
- SageMaker permissions
- States (StepFunction) permissions
- CloudWatch permissions
Let create a role by using CDK
const role = new aws_iam.Role(this, "RoleForPCAPipelineDemo", {roleName: "RoleForPCAPipelineDemo",assumedBy: new aws_iam.CompositePrincipal(new aws_iam.ServicePrincipal("states.amazonaws.com"),new aws_iam.ServicePrincipal("sagemaker.amazonaws.com")),});role.addManagedPolicy(aws_iam.ManagedPolicy.fromAwsManagedPolicyName("AmazonSageMakerFullAccess"));// logsrole.addManagedPolicy(aws_iam.ManagedPolicy.fromAwsManagedPolicyName("CloudWatchEventsFullAccess"));// create pipeline using stepfunctionrole.addManagedPolicy(aws_iam.ManagedPolicy.fromAwsManagedPolicyName("AWSStepFunctionsFullAccess"));role.addToPolicy(new aws_iam.PolicyStatement({effect: Effect.ALLOW,resources: ["*"],actions: ["s3:*"],}));