
Introduction#
GitHub this note shows basics concepts of SageMaker Estimator API
- Estimator: Built-In Algorithm, Framework, BYOM
- Estimator: Training Job
- Estimator: Data Access
Estimator Class#
An estimator is an abstraction object with methods for training a model, deploying a model into an endpoint. It means that it will call AWS APIs under the hood to create training job, mode, endpoint, etc. Without this abstraction, it is possible to directly call APIs such as with Boto3 to create model, train, deploy. It has at least the following properties
- Container image (container image uri)
- Instance type which run the container
- IAM Role for accessing S3 (data, code), CloudWatch logs
Estimator class is organized into with based and child classes
- Built-In Algorithm
- Framework Algorithm
- Bring Your Own Model (BYOM)
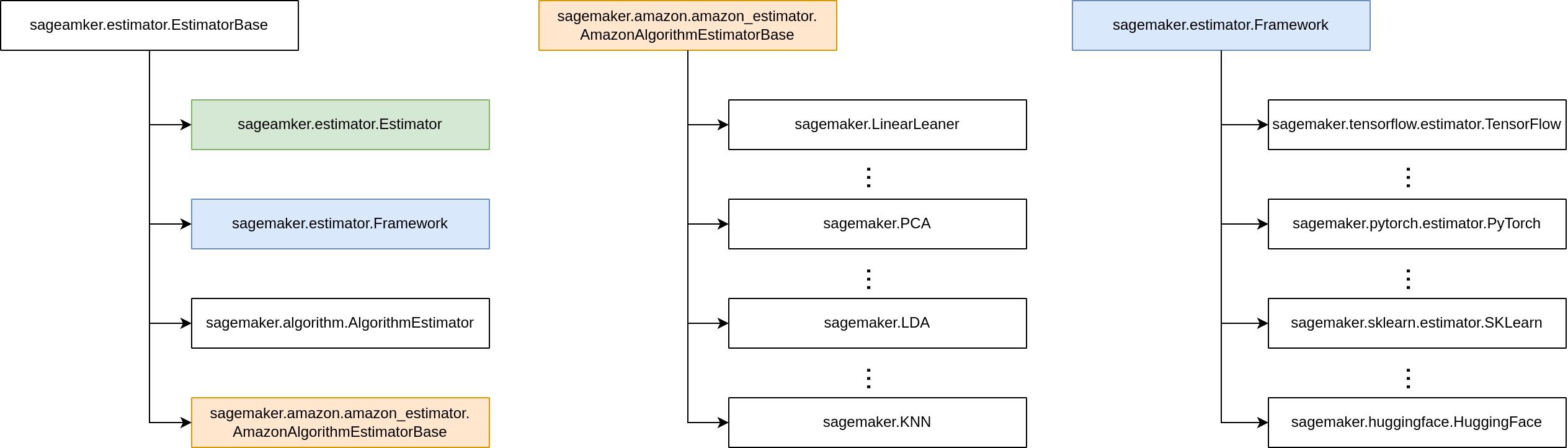
Let create a estimator for PCA (built-in algorithm) using the based estimator class. First we need to find the iamge uri
image_uri = sagemaker.estimator.image_uris.retrieve(framework="pca",region=os.environ["REGION"],version="0.23-1",instance_type="ml.m4.xlarge",)
Then we can create an estimator using the SageMaker based Estimator class
estimator = sagemaker.estimator.Estimator(image_uri=image_uri,instance_type="ml.m4.xlarge",instance_count=1,# output_path="",role=os.environ["SAGEMAKER_ROLE"],)
Then we can train the model by calling fit method on the estimator. Under the hood, this method call an API to create a training job docs. Please check Boto3 for detail
estimator.set_hyperparameters(feature_dim=4,num_components=3,mini_batch_size=200)
Train the model by creating a training job either by estimator.fit() or other methods to create a training job such as Boto3, TrainingStep in a pipeline.
estimator.fit(inputs={"train": s3_train_data})
Finally, we can deploy the model as a endpoint and invoke it. Under the hood, this method call an API to create an serving endpoint config and endpoint docs. Please check Boto3 for detail
predictor = estimator.deploy(initial_instance_count=1,instance_type="ml.t2.medium")
Take note the endpoint and invoke. Under the hood, this method send a HTTP request to the endpoint
predictor.predict(clean_ecg[:10000,:])
Estimator Data Access#
Basically, trining job run containers with training script, model (image uri), and training data. Since the training data stored in S3, or local, or FileSystem, we need to understand how data is passed from sources to containers. Please check blog to select suitable input mode
- S3 Data
- FileSystem
- Local
Estimator Data Input#
There are some options to feed training data into a estimator.fit() for training docs. Under the hood, it call an API to create an training job with input and output data InputDataConfig as
{"ChannelName": "string","DataSource": {"S3DataSource": {'S3DataType': 'ManifestFile'|'S3Prefix'|'AugmentedManifestFile',"S3Uri": "string",'S3DataDistributionType': 'FullyReplicated'|'ShardedByS3Key',"AttributeNames": ["string"],"InstanceGroupNames": ["string"]},"FileSystemDataSource": {"FileSystemId": "string",'FileSystemAccessMode': 'rw'|'ro','FileSystemType': 'EFS'|'FSxLustre',"DirectoryPath": "string"}},"ContentType": "string",'CompressionType': 'None'|'Gzip','RecordWrapperType': 'None'|'RecordIO','InputMode': 'Pipe'|'File'|'FastFile',"ShuffleConfig": {"Seed": 123}}
The Estimator object provide several options (interface) to feed data into a training job, but under the hood it call an API with the above spec.
- Option 1. TrainingInput
train_data = sagemaker.inputs.TrainingInput(s3_train_data,distribution="FullyReplicated",content_type="text/csv",s3_data_type="S3Prefix",record_wrapping=None,compression=None,)validation_data = sagemaker.inputs.TrainingInput(s3_validation_data,distribution="FullyReplicated",content_type="text/csv",s3_data_type="S3Prefix",record_wrapping=None,compression=None,)# feed data to estimator for traininglinear.fit(inputs={"train": train_data, "validation": validation_data}, job_name=job_name)
Another example with PCA HERE
image_uri = image_uris.retrieve(framework="pca",region=os.environ["REGION"],instance_type="t2.medium",)estimator = sagemaker.estimator.Estimator(role=config["SAGEMAKER_ROLE"],image_uri=image_uri,instance_count=1,instance_type="ml.c4.xlarge",)estimator.set_hyperparameters(feature_dim=4,num_components=3,mini_batch_size=200,)estimator.fit(inputs={"train": TrainingInput(content_type="text/csv;label_size=0",s3_data=f"s3://{config['SAGEMAKER_BUCKET']}/pca-processed-data",)})
- Option 2. S3 Data Location
s3_train_data = f"s3://{bucket}/{prefix}/train/{key}"pca = sagemaker.estimator.Estimator(container,role,instance_count=1,instance_type="ml.c4.xlarge",output_path=output_location,sagemaker_session=sess,)pca.set_hyperparameters(feature_dim=50000,num_components=10,subtract_mean=True,algorithm_mode="randomized",mini_batch_size=200,)pca.fit(inputs={"train": s3_train_data})
- Option 3. Local Mode
inputs = sagemaker_session.upload_data(path='data', bucket=bucket, key_prefix='data/cifar10')cifar10_estimator = PyTorch(py_version='py3',entry_point='source/cifar10.py',role=role,framework_version='1.7.1',instance_count=1,instance_type='local')cifar10_estimator.fit(inputs)