
Introduction#
GitHub this notes show how IAM and LakeFormation togeter control access to data lake.
- Register an admin to LakeFormation
- Register S3 buckets to LakeFormation
- Grant (fine-grained) permissions to a Data Scientist
- Grant (fine and coarse grained) permissions to a Glue Role
- Revoke IAMAllowedPrincipals
- Use correct method write_dynamic_frame.from_catalog
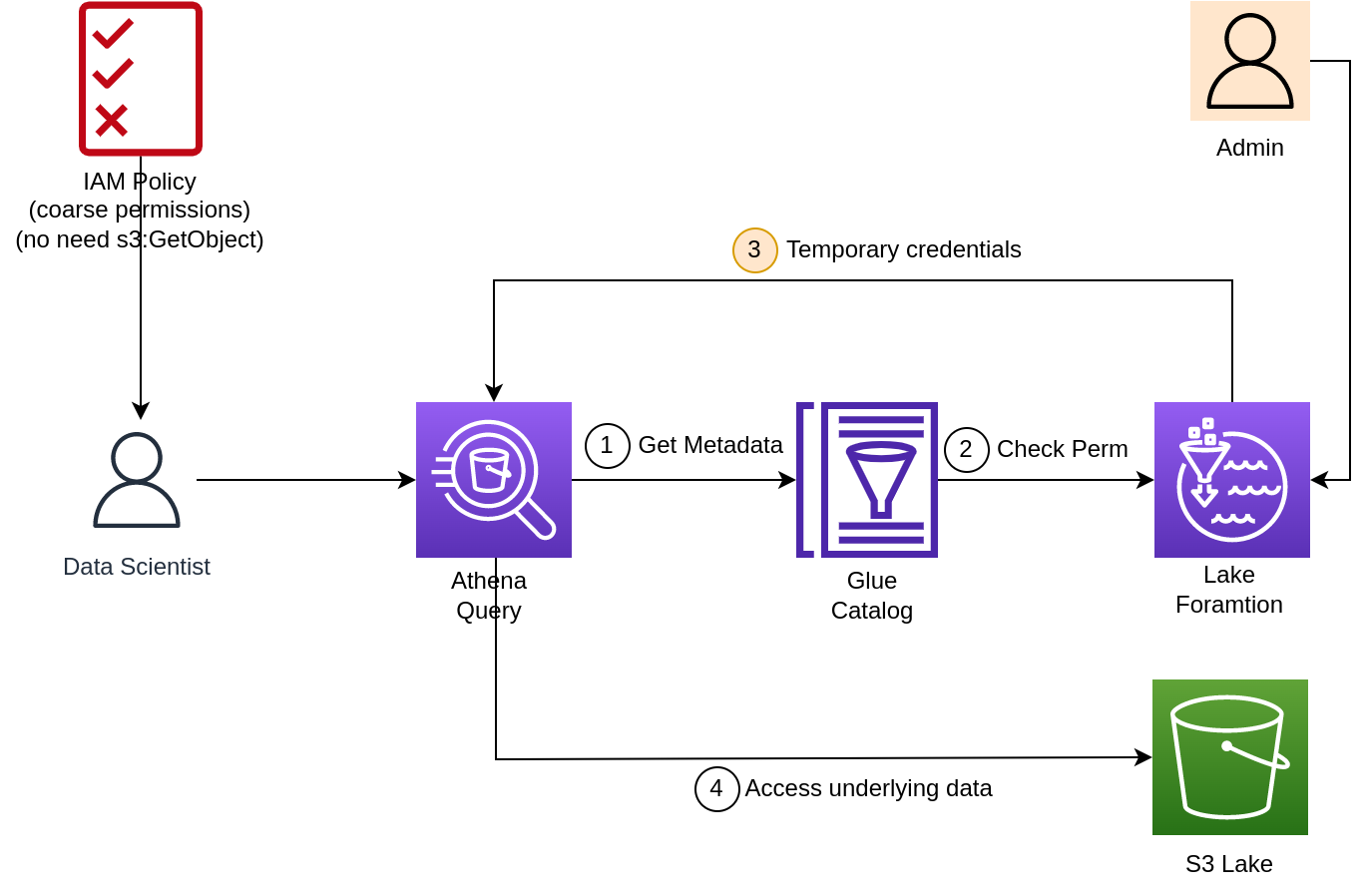
LakeFormation#
Register an admin to LakeFormation, in this case the admin is CF execution role
this.lakeCdkAmin = new aws_lakeformation.CfnDataLakeSettings(this,'LakeFormationAdminSetting',{admins: [{dataLakePrincipalIdentifier: Fn.sub((this.synthesizer as DefaultStackSynthesizer).cloudFormationExecutionRoleArn)}]})
Create a S3 bucket for lake
const bucket = new aws_s3.Bucket(this, 'S3LakeBucketDemo', {bucketName: props.s3LakeName,removalPolicy: RemovalPolicy.DESTROY,autoDeleteObjects: true})
Register data source buckets to lake
var registers: aws_lakeformation.CfnResource[] = []props.registerBuckets.map(bucket => {registers.push(new aws_lakeformation.CfnResource(this, `RegsiterBucketToLake-${bucket}`, {resourceArn: `arn:aws:s3:::${bucket}`,useServiceLinkedRole: true}))})
Grant Permissions#
- Create an IAM user with password stored in Secret
- Coarse permissions by IAM
- Fine permissions by LakeFormation
Create an IAM user with passwrod stored in secret values
const secret = new aws_secretsmanager.Secret(this, `${props.userName}Secret`, {secretName: `${props.userName}Secret`,generateSecretString: {secretStringTemplate: JSON.stringify({ username: props.userName }),generateStringKey: 'password'}})// create an iam user for data analyst (da)const daUser = new aws_iam.User(this, `${props.userName}IAMUser`, {userName: props.userName,password: secret.secretValueFromJson('password'),passwordResetRequired: false})
DS need to save query result to Athena query result location
daUser.addToPolicy(new aws_iam.PolicyStatement({effect: Effect.ALLOW,actions: ['s3:*'],resources: [`arn:aws:s3:::${props.athenaResultBucket}/*`,`arn:aws:s3:::${props.athenaResultBucket}`]}))
Coarse grained permission by IAM
daUser.addManagedPolicy(aws_iam.ManagedPolicy.fromAwsManagedPolicyName('AmazonAthenaFullAccess'))
For DS to see Glue catalog databases, and table we need below permissions. In addition, DS need to get some permissions from LakeFormation
daUser.addToPolicy(new aws_iam.PolicyStatement({effect: Effect.ALLOW,actions: ['lakeformation:GetDataAccess','glue:GetTable','glue:GetTables','glue:SearchTables','glue:GetDatabase','glue:GetDatabases','glue:GetPartitions','lakeformation:GetResourceLFTags','lakeformation:ListLFTags','lakeformation:GetLFTag','lakeformation:SearchTablesByLFTags','lakeformation:SearchDatabasesByLFTags'],resources: ['*']}))
Fine-grained permissions by LakeFormation, control access to tables, and database in Glue catalog. It is possible to control to column level and use Tag for scale.
const tablePermission = new aws_lakeformation.CfnPrincipalPermissions(this,`${props.userName}-ReadTableLake-2`,{permissions: props.databasePermissions,permissionsWithGrantOption: props.databasePermissions,principal: {dataLakePrincipalIdentifier: daUser.userArn},resource: {table: {catalogId: this.account,databaseName: props.databaseName,tableWildcard: {}}}})new aws_lakeformation.CfnPrincipalPermissions(this,`${props.userName}-ReadTableLake-4`,{permissions: props.databasePermissions,permissionsWithGrantOption: props.databasePermissions,principal: {dataLakePrincipalIdentifier: daUser.userArn},resource: {database: {catalogId: this.account,name: props.databaseName}}})
ETL WorkFlow Role#
- Coarse permissions with IAM
- Fine permissions with LakeFormation
- Permissions: read S3, write S3, create catalog tables
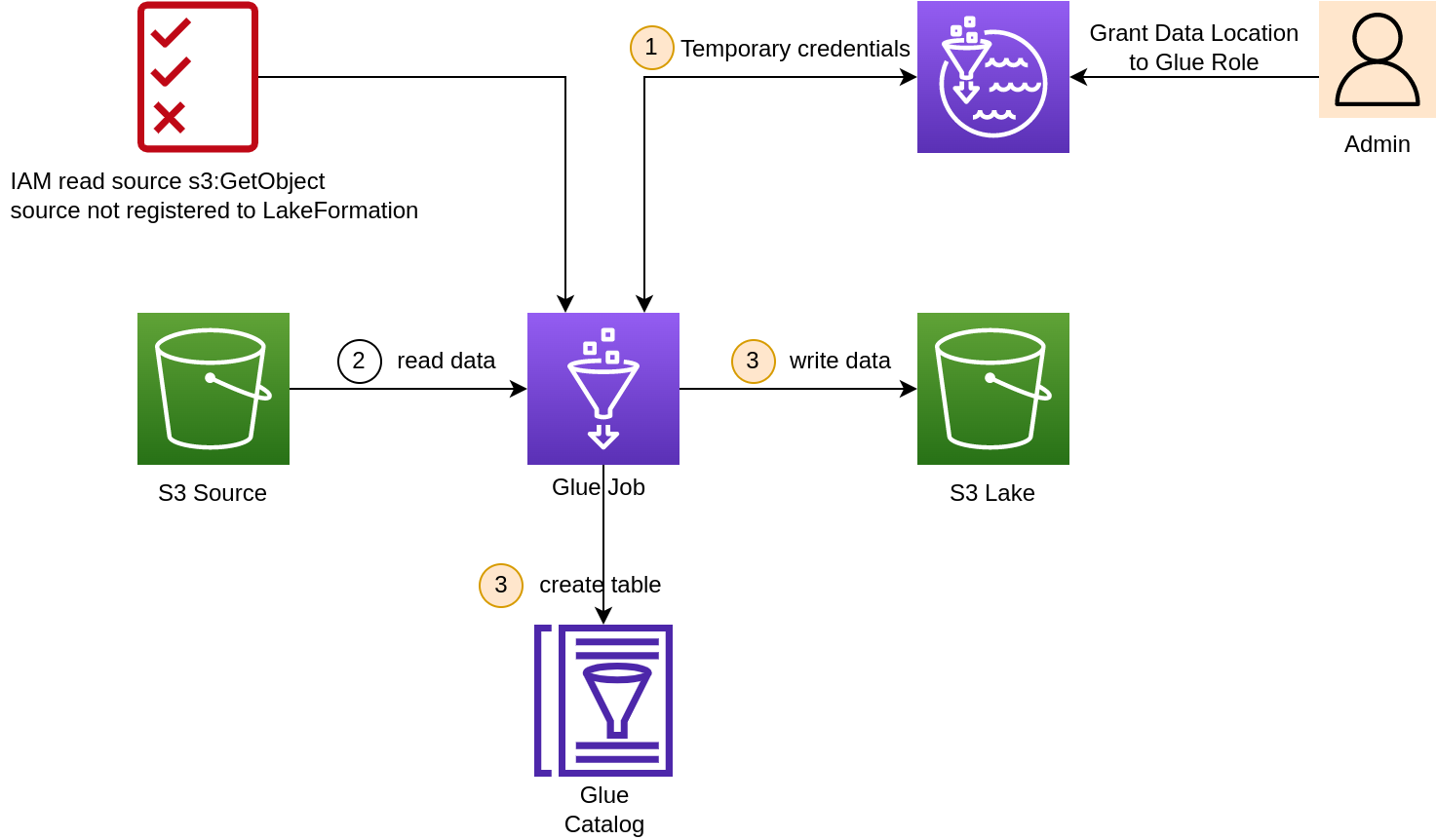
First, coarse permissions with IAM, need to attach AWSGlueServiceRole policy
const role = new aws_iam.Role(this, 'LakeFormationWorkFlowRole', {roleName: 'LakeFormationWorkFlowRole',assumedBy: new aws_iam.ServicePrincipal('glue.amazonaws.com')})// remove this and checkrole.addManagedPolicy(aws_iam.ManagedPolicy.fromAwsManagedPolicyName('service-role/AWSGlueServiceRole'))role.addManagedPolicy(aws_iam.ManagedPolicy.fromAwsManagedPolicyName('CloudWatchAgentServerPolicy'))
Second, Glue role need permissions to read data from source and write to a S3 lake bucket. It also need iam:PassRole and lakeformation:GetDataAccess
const policy = new aws_iam.Policy(this, 'PolicyForLakeFormationWorkFlow', {policyName: 'PolicyForLakeFormationWorkFlow',statements: [// pass iam role or follow name convention// AWSGlueServiceRoleDefaultnew aws_iam.PolicyStatement({actions: ['iam:PassRole', 'iam:GetRole'],effect: Effect.ALLOW,resources: ['*']}),// read data from s3 sourcenew aws_iam.PolicyStatement({actions: ['s3:GetObject'],effect: Effect.ALLOW,resources: [`${props.sourceBucketArn}/*`]}),new aws_iam.PolicyStatement({actions: ['lakeformation:GetDataAccess','lakeformation:GrantPermissions'],effect: Effect.ALLOW,resources: ['*']})]})policy.attachToRole(role)
Fine permission with LakeFormation so that the Glue role can:
- Create catalog tables in a database
- Write data to the table's underlying data location in S3
const grant = new aws_lakeformation.CfnPrincipalPermissions(this,'GrantLocationPermissionGlueRole-1',{permissions: ['DATA_LOCATION_ACCESS'],permissionsWithGrantOption: ['DATA_LOCATION_ACCESS'],principal: {dataLakePrincipalIdentifier: role.roleArn},resource: {dataLocation: {catalogId: this.account,resourceArn: `${props.destBucketArn}`}}})
Glue Job Script#
Please use correct method to write dataframe to the table's udnerlying data location in S3.
- correct: write_dynamic_frame.from_catalog
- incorrect: write_dynamic_frame.from_options
Quoted from docs Writes a DynamicFrame using the specified catalog database and table name.
glueContext.write_dynamic_frame.from_catalog(frame=S3bucket_node1,database= "default",table_name="amazon_reviews_parquet_table",transformation_ctx="S3bucket_node3",)
The incorrect one
S3bucket_node5 = glueContext.getSink(path="s3://{0}/amazon-review-tsv-parquet/".format(data_lake_bucket),connection_type="s3",updateBehavior="UPDATE_IN_DATABASE",partitionKeys=[],# compression="snappy",enableUpdateCatalog=True,transformation_ctx="write_sink",)S3bucket_node5.setCatalogInfo(catalogDatabase="default",catalogTableName="amazon_review_tsv_parquet")S3bucket_node5.setFormat("glueparquet")S3bucket_node5.writeFrame(S3bucket_node1)
Another incorrect one
S3bucket_node3 = glueContext.write_dynamic_frame.from_options(frame=S3bucket_node1,connection_type="s3",format="glueparquet",connection_options={"path": "s3://{0}/parquet/".format(data_lake_bucket),"partitionKeys": ["product_category"],"enableUpdateCatalog": True,"database":"default","table":"amazon_reviews_parquet_table",},format_options={"compression": "uncompressed"},transformation_ctx="S3bucket_node3",)
Troubeshooting#
When creating a database in Lake Formation catalog, it is possible to specify location (S3 path of the database). Choose an Amazon S3 path for this database, which eliminates the need to grant data location permissions on catalog table paths that are this location’s children.
-
Follow the convention name for GlueServiceRoleDefault
-
Check the Lake Formation Permission and Data Location before CDK deploy
-
Spark DataFrame enforce data type and schema
from pyspark.sql.types import StructType, StringType, IntegerTypeschema = StructType() \.add("marketplace",StringType(),True) \.add("customer_id",StringType(),True) \.add("review_id",StringType(),True) \.add("product_id",StringType(),True) \.add("product_parent",StringType(),True) \.add("product_title",StringType(),True) \.add("product_category",StringType(),True) \.add("star_rating",StringType(),True) \.add("helpful_vote",StringType(),True) \.add("total_vote",StringType(),True) \.add("vine",StringType(),True) \.add("verified_purchase",StringType(),True) \.add("review_headline",StringType(),True) \.add("review_body",StringType(),True) \.add("myyear",StringType(),True)df = spark_session.read.format("csv")\.option("header", False)\.option("delimiter", "\t")\.option("quote", '"')\.schema(schema)\.load("s3://amazon-reviews-pds/tsv/amazon_reviews_us_Sports_v1_00.tsv.gz")df.selectExpr("cast(star_rating as int) star_rating")
- Convert Spark DataFrame to Glue DataFrame
from awsglue.dynamicframe import DynamicFrameglue_df = DynamicFrame.fromDF(df, glueContext, "GlueDF")glueContext.write_dynamic_frame.from_catalog(frame=glue_df,database= "default",table_name=table_name,transformation_ctx="S3bucket_node3",)
Column Level Access#
It is possilbe to grant a principal to SELECT some columns (only work with SELECT)
new aws_lakeformation.CfnPrincipalPermissions(this,"TableWithColumnsResourceSelectOnly",{permissions: ["SELECT"],permissionsWithGrantOption: ["SELECT"],principal: {dataLakePrincipalIdentifier: principalArn,},resource: {tableWithColumns: {catalogId: this.account,databaseName: databaseName,name: tableName,columnNames: columnNames,},},});
LakeFormation Tag#
LF-Tags enable managing permissions at scale compared with using pure IAM. For example, let use LF-Tags to grant a data scientist to select only NON-PII columns
First, create environment and privacy tag
// create environment tagconst envTag = new aws_lakeformation.CfnTag(this, "EnvironmentTag", {tagKey: "environment",tagValues: ["production"],});// create privacy tagconst privacyTag = new aws_lakeformation.CfnTag(this, "PrivacyTag", {tagKey: "privacy",tagValues: ["open"],});
Second, associate the environment tag with default database and spcific databases, so the data scientist can see specific database
const associateEnvironment = new aws_lakeformation.CfnTagAssociation(this,"EnvironmentTagAssociation",{lfTags: [{catalogId: this.account,tagKey: envTag.tagKey,tagValues: envTag.tagValues,},],resource: {database: {catalogId: this.account,name: databaseName},table: {catalogId: this.account,databaseName: databaseName,name: tableName,tableWildcard: {},},},});
Then, associate privacy tag with NON-PII columns such as product_id
const associatePrivacy = new aws_lakeformation.CfnTagAssociation(this,"PrivacyTagAssociation",{lfTags: [{catalogId: this.account,tagKey: privacyTag.tagKey,tagValues: privacyTag.tagValues,},],resource: {tableWithColumns: {catalogId: this.account,columnNames: ["marketplace", "product_id", "product_title"],databaseName: databaseName,name: tableName,},},});
Third, now we need to grant the data scientist to see specified tables
const envTagPermission = new aws_lakeformation.CfnPrincipalPermissions(this, "EnvTagDataScientistDescribe", {permissions: ["DESCRIBE"],permissionsWithGrantOption: ["DESCRIBE"],principal: {dataLakePrincipalIdentifier: principalArn,},resource: {lfTagPolicy: {catalogId: this.account,expression: [{tagKey: envTag.tagKey,tagValues: envTag.tagValues,},],resourceType: "DATABASE",},},});
Finally, grant the data scientist to query or select the specific columns
const privacyTagPermission = new aws_lakeformation.CfnPrincipalPermissions(this, "PrivayTagDataScientistSelect", {permissions: ["SELECT"],permissionsWithGrantOption: ["SELECT"],principal: {dataLakePrincipalIdentifier: principalArn,},resource: {lfTagPolicy: {catalogId: this.account,expression: [{tagKey: privacyTag.tagKey,tagValues: privacyTag.tagValues,},],resourceType: "TABLE",},},});