
Introduction#
This GitHub shows
- kinesis cli and producer
- develop with kinesis studio zeppeline notebook
- develop and deploy kda app
- some key concepts of data streaming with flink
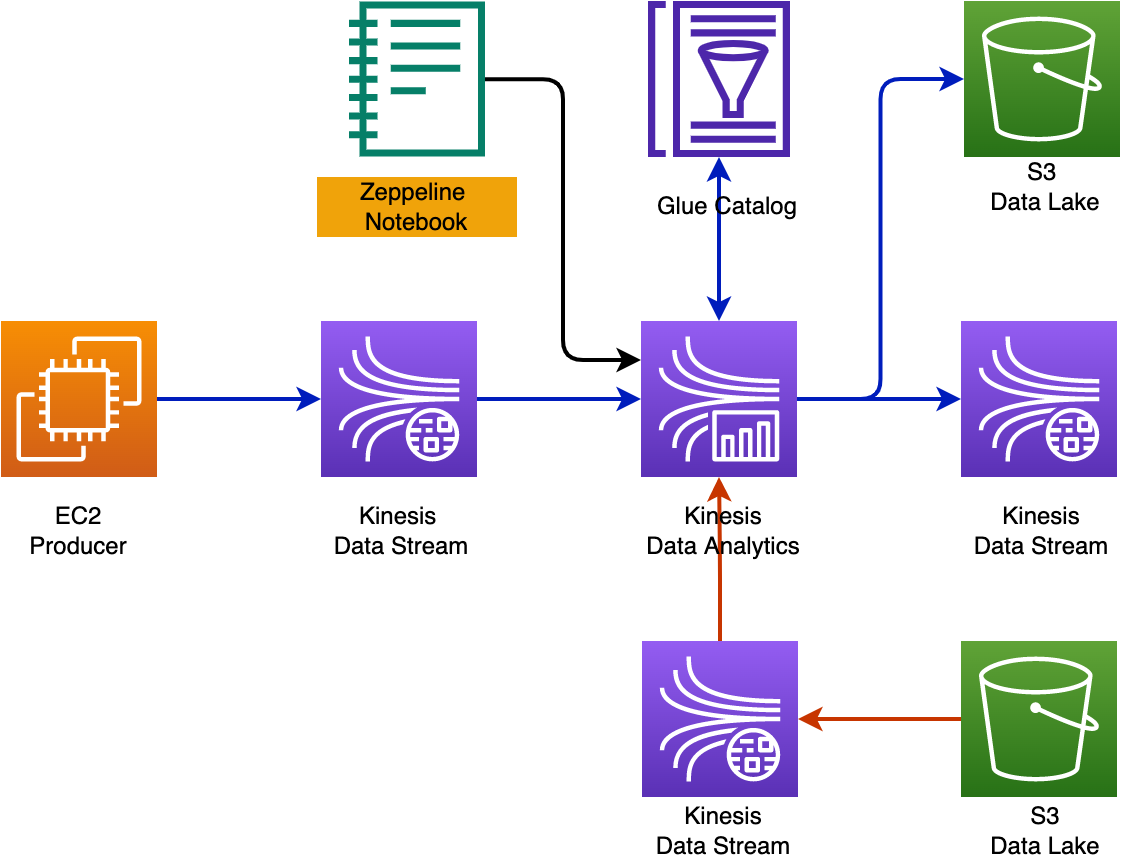
Kinesis CLI#
aws kinesis get-shard-iterator --shard-id shardId-000000000000 --shard-iterator-type TRIM_HORIZON
aws kinesis get-shard-iterator \--stream-name input-stream \--shard-id shardId-000000000001 \--shard-iterator-type LATEST
Get Records
aws kinesis get-records \--shard-iterator AAAAAAAAAAGQSzIrfkjBufIU6bUR0UXRSoPbPPp0TWaau6wKZgoFArI+lFmGXr3Z2myZwGqUmD/3sWjUXSTYvVCv+dFfu+06g/C0Jmbnzno0FuNI9a2rK+OFTYH0+61fa6efOR4xv3XdVbrzNwT1dJXV4/BGvz0x2GtOh4Go6EUbwcgpL5xdkzjkaT+sg2kBwnfjxTSFkPP/mp7ZkSyc3rU6EOLhLoG1q+CZZJfGX2Oi1ZayHMqcBQ==
Enhanced Fan-Out
aws kinesis register-stream-consumer \--stream-arn arn:aws:kinesis:ap-southeast-1:681505416554:stream/taxi-stream \--consumer-name HelloConsumer
Conda Environment#
First download miniconda from [here]https://repo.anaconda.com/miniconda/Miniconda3-py39_23.5.2-0-Linux-x86_64.sh, then install miniconda
bash Miniconda3-latest-Linux-x86_64.sh
Create environment
conda create -n my-new-environment pip python=3.8
List environment
conda infor --envs
Activate environment
conda activate my-new-environment
Shard Limit#
The read limit 5 transactions per seconds
- Kinesis max shard reads/sec and multiple consumers
- idleTimeBetweenReadsInMillis
- idleTimeBetweenReadsInMillis GitHub
# haimtran 20/07/2023# multiple consumers reading a shard# to see the exceed read throughput errorimport boto3import osfrom multiprocessing import Processfrom botocore.exceptions import ClientErrorimport sys# parameterseREGION = "ap-southeast-1"STREAM_NAME = "stock-input-stream"NUM_CONSUMER = 10# kinesis clientclient = boto3.client("kinesis", region_name=REGION)# get recordsdef get_records(max_records=10000):"""get records from a stream"""response = client.get_shard_iterator(StreamName = STREAM_NAME,ShardId="shardId-000000000001",ShardIteratorType="LATEST")# shard interatorshard_iterator = response["ShardIterator"]# get recordsrecord_count = 0while record_count < max_records:try:response = client.get_records(ShardIterator = shard_iterator,Limit=10)# recordrecords = response["Records"]# next iteratorshard_iterator = response["NextShardIterator"]# print to std outprint("id {0} records {1}".format(os.getpid(), records))# print to log filerecord_count += len(records)# time.sleep(1)except ClientError as error:print("================================================ \n")print(error)print("================================================ \n")os.system("pkill -f get-stock-process.py")if __name__=="__main__":# get_records()for k in range(1, NUM_CONSUMER):Process(target=get_records).start()
Develop Notebook#
- create source table
- do some transformation
- create sink table
First, let create a table
CREATE TABLE stock_table (ticker VARCHAR(6),price DOUBLE,event_time TIMESTAMP(3),WATERMARK FOR event_time AS event_time - INTERVAL '5' SECOND)PARTITIONED BY (ticker)WITH ('connector' = 'kinesis','stream' = 'stock-input-stream','aws.region' = 'ap-southeast-1','scan.stream.initpos' = 'LATEST','format' = 'json','json.timestamp-format.standard' = 'ISO-8601') """)
Seccond, please pay attention to the watermakr as it is required for windowing and action here. Let use a tumbling window to calculate average stock price over each 10 second window
%flink.ssql(type=update)SELECTstock_table.ticker as ticker,AVG(stock_table.price) AS avg_price,TUMBLE_ROWTIME(stock_table.event_time, INTERVAL '10' second) as time_eventFROM stock_tableGROUP BY TUMBLE(stock_table.event_time, INTERVAL '10' second), stock_table.ticker;
Third, let use slidding window to calcualte average price over a window width of 1 minute and update each 10 seconds
SELECTstock_table.ticker as ticker,AVG(stock_table.price) AS avg_price,HOP_ROWTIME(stock_table.event_time, INTERVAL '10' second, INTERVAL '1' minute) as hop_timeFROM stock_tableGROUP BY HOP(stock_table.event_time, INTERVAL '10' second, INTERVAL '1' minute), stock_table.ticker;
Finally, let create a sink table to write data to s3. Before that we need to enable checkpointing each minute
%flink.pyflinkst_env.get_config().get_configuration().set_string("execution.checkpointing.interval", "1min")
Then create a sink table for writting to s3
CREATE TABLE stock_output_table(ticker VARCHAR(6),price DOUBLE,event_time TIMESTAMP(3))PARTITIONED BY (ticker)WITH ('connector'='filesystem','path'='s3a://{1}/','format'='csv','sink.partition-commit.policy.kind'='success-file','sink.partition-commit.delay' = '1 min')
Finally insert data into the sink table
INSERT INTO stock_output_table SELECT * FROM stock_able
Cancel the writting s3 job
%flink.pyflinkprint(table_result.get_job_client().cancel())
Deploy Notebook#
Please remove all select operator. First, create variables
%flink.pyflinkinput_table_name = "stock_input_table"output_table_name = "stock_output_table"bucket_name = "data-lake-demo-17072023"region = "ap-southeast-1"input_stream_name = "stock-input-stream"prefix = "stock-data"
Then create a source table
%flink.pyflinkst_env.execute_sql("""CREATE TABLE {0}(ticker VARCHAR(6),price DOUBLE,event_time TIMESTAMP(3),WATERMARK FOR event_time AS event_time - INTERVAL '5' SECOND)PARTITIONED BY (ticker)WITH ('connector' = 'kinesis','stream' = '{1}','aws.region' = '{2}','scan.stream.initpos' = 'LATEST','format' = 'json','json.timestamp-format.standard' = 'ISO-8601') """.format(input_table_name, input_stream_name, region))
Setup the checkpoint 1 minute
%flink.pyflinkst_env.get_config().get_configuration().set_string("execution.checkpointing.interval", "1min")
Create a sink table
%flink.pyflinkst_env.execute_sql("""CREATE TABLE {0}(ticker VARCHAR(6),price DOUBLE,event_time TIMESTAMP(3))PARTITIONED BY (ticker)WITH ('connector'='filesystem','path'='s3a://{1}/{2}/','format'='csv','sink.partition-commit.policy.kind'='success-file','sink.partition-commit.delay' = '1 min')""".format(output_table_name, bucket_name, prefix))
Insert data into sink table
%flink.pyflinktable_result = st_env.execute_sql("INSERT INTO {0} SELECT * FROM {1}".format(output_table_name, input_table_name))
Cancel the job in notebook in case
table_result.get_job_client().cancel()
Develop App#
- project structure
- configuration
- iam role
- tumbling window
Project structure
|--app|--application_properties.json|--streaming-file-sink.py|--deploy.sh
Follow this docs to create configuration for the app
[{"PropertyGroupId": "consumer.config.0","PropertyMap": {"input.stream.name": "stock-input-stream","aws.region": "ap-southeast-1","scan.stream.initpos": "LATEST"}},{"PropertyGroupId": "kinesis.analytics.flink.run.options","PropertyMap": {"python": "streaming-file-sink.py","jarfile": "flink-sql-connector-kinesis-1.15.2.jar"}},{"PropertyGroupId": "sink.config.0","PropertyMap": {"output.bucket.name": "data-lake-demo-17072023"}},{"PropertyGroupId": "producer.config.0","PropertyMap": {"output.stream.name": "stock-output-stream","shard.count": "1","aws.region": "ap-southeast-1"}}]
Let double check the iam role attached to the flink job. Here is trusted policy
{"Version": "2012-10-17","Statement": [{"Effect": "Allow","Principal": {"Service": "kinesisanalytics.amazonaws.com"},"Action": "sts:AssumeRole"}]}
Permissions for demo purpose
CloudWatchFullAccessCloudWatchLogsFullAccessAmazonKinesisFullAccessAmazonS3FullAccess
Finally here is the logical code for sink table writting to S3
def create_sink_table(table_name, bucket_name):return """ CREATE TABLE {0} (ticker VARCHAR(6),price DOUBLE,event_time TIMESTAMP(3))PARTITIONED BY (ticker)WITH ('connector'='filesystem','path'='s3a://{1}/','format'='json','sink.partition-commit.policy.kind'='success-file','sink.partition-commit.delay' = '1 min') """.format(table_name, bucket_name)
Insert to the sink table
table_result = table_env.execute_sql("INSERT INTO {0} SELECT * FROM {1}".format(output_table_name, input_table_name))
Simple put data to the stock-input-stream to test output in s3
import datetimeimport jsonimport randomimport boto3import timeSTREAM_NAME = "stock-input-stream"REGION = "ap-southeast-1"def get_data():return {'event_time': datetime.datetime.now().isoformat(),'ticker': random.choice(['AAPL', 'AMZN', 'MSFT', 'INTC', 'TBV']),'price': round(random.random() * 100, 2) }def generate(stream_name, kinesis_client):while True:data = get_data()print(data)kinesis_client.put_record(StreamName=stream_name,Data=json.dumps(data),PartitionKey="partitionkey")time.sleep(1)if __name__ == '__main__':generate(STREAM_NAME, boto3.client('kinesis', region_name = REGION))