
Introduction#
- Glue crawler crawl delta lake format
- Athena query delta lake format
Data#
Download sample data to a bucket
aws s3 sync s3://aws-bigdata-blog/artifacts/delta-lake-crawler/sample_delta_table/ s3://your_s3_bucket/data/sample_delta_table
Upload sample data from local data to a bucket
aws s3 cp . s3://BUCKET/sample-delta-table/ --recursive
Crawler#
Create a crawler to crawl the delta table, then can query using Athena as normal
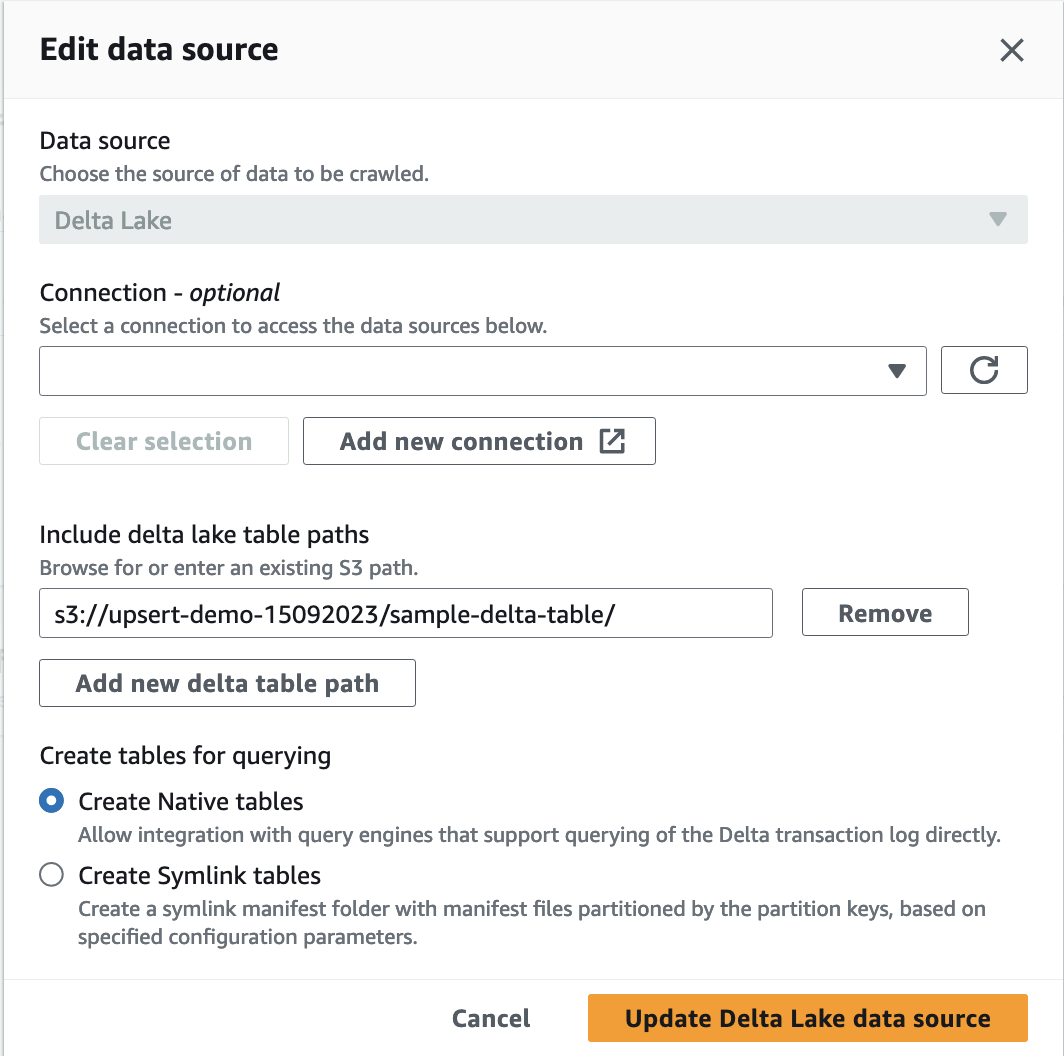
When the crawl complete we see a new table in Glue Catalog
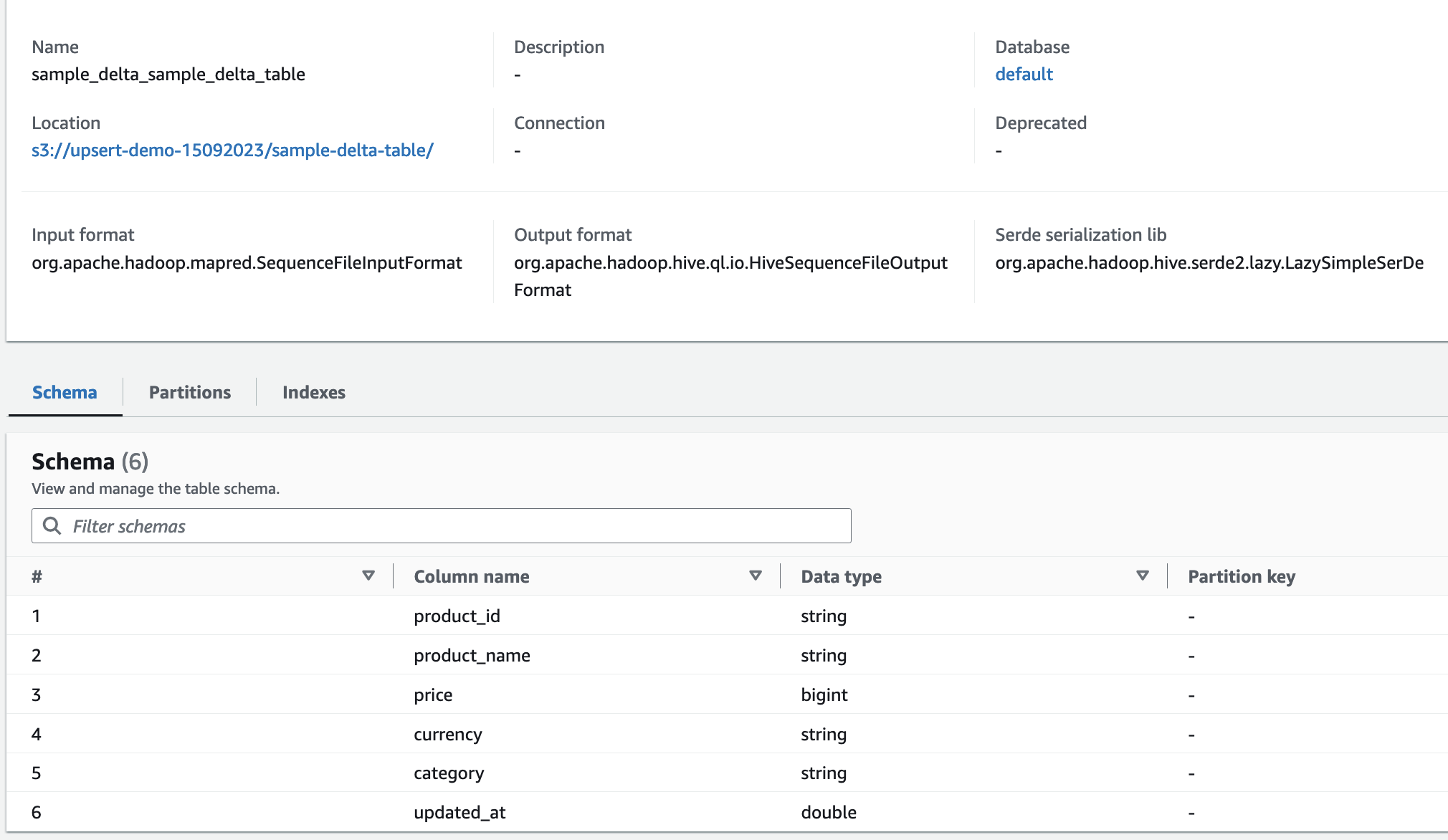
Athena Notebook#
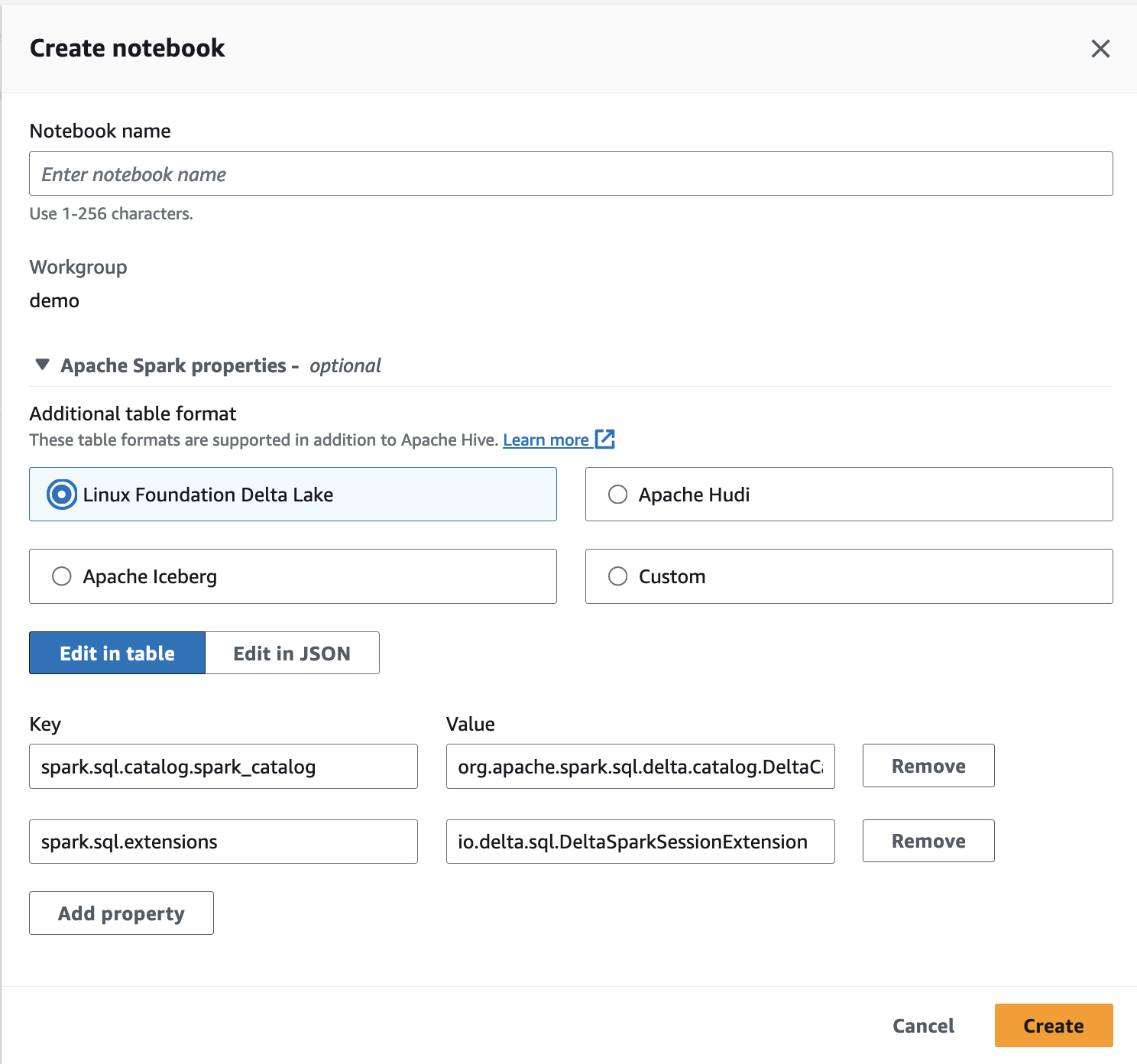
It is possible to query the delta table using either Athena query editor or Spark notebook. For Spark notebook, first create a workgroup then create a notebook as below.
[!IMPORTANT] Please select Linux Foundation Delta Lake option. Please ensure IAM role for the workgroup has perrmissions to read s3 and glue catalog.
[!NOTE] Athena spark notebook already install delta lake packag
Let write simple notebook cells
DB_NAME = "default"TABLE_NAME = "sample_delta_sample_delta_table"TABLE_S3_LOCATION = "s3://$BUCKET/sample-delta-table/"
and query using sql
spark.sql("SELECT * FROM {}.{}".format(DB_NAME, TABLE_NAME)).show()
Glue Notebook#
It is possible to query and operate on the delta table from the Glue interactive notebook
[!NOTE] Setup a proper IAM role for the Glue notebook (iam passroles)
first cell
%glue_version 3.0%%configure{"--datalake-formats": "delta"}
create spark session and or context
%idle_timeout 2880%glue_version 3.0%worker_type G.1X%number_of_workers 5import sysfrom awsglue.transforms import *from awsglue.utils import getResolvedOptionsfrom pyspark.context import SparkContextfrom awsglue.context import GlueContextfrom awsglue.job import Jobsc = SparkContext.getOrCreate()glueContext = GlueContext(sc)spark = glueContext.spark_sessionjob = Job(glueContext)
then query using sql cell
%%sqlSELECT * FROM `default`.`sample_delta_sample_delta_table` limit 10
Delta Table Python#
From the Glue notebook it is possible to import and use the DeltaTable lib
from delta.tables import DeltaTable
Then do as normal
df = DeltaTable.forPath(spark, "s3://upsert-demo-15092023/sample-delta-table/")df.toDF().show()
[!NOTE] We might need to create a spark session with below configuration to support Delta Lake
spark = SparkSession \.builder \.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") \.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog") \.getOrCreate()
UPSERT Example#
The full notebook is HERE
- Read fullload data csv in s3
- Write to a delta table in s3 (targat table)
- Read update data in csv (cdc updates)
- UPMERGE udpates into target
Let create new Glue notebook
%glue_version 3.0%%configure{"--datalake-formats": "delta"}
Create new session
%idle_timeout 2880# %glue_version 3.0%worker_type G.1X%number_of_workers 5import sysfrom awsglue.transforms import *from awsglue.utils import getResolvedOptionsfrom pyspark.context import SparkContextfrom awsglue.context import GlueContextfrom awsglue.job import Jobsc = SparkContext.getOrCreate()glueContext = GlueContext(sc)spark = glueContext.spark_sessionjob = Job(glueContext)
Step 1. read fullload data (csv) from s3 into dataframe
from delta.tables import DeltaTablefrom pyspark.sql.types import *from pyspark.sql.functions import colfrom pyspark.sql.functions import exprschema = StructType() \.add("policy_id",IntegerType(),True) \.add("expiry_date",DateType(),True) \.add("location_name",StringType(),True) \.add("state_code",StringType(),True) \.add("region_name",StringType(),True) \.add("insured_value",IntegerType(),True) \.add("business_type",StringType(),True) \.add("earthquake_coverage",StringType(),True) \.add("flood_coverage",StringType(),True)
Read fullload data from csv in s3
# read the full loadsdf = spark.read.format("csv").option("header",True).schema(schema).load(f's3://{BUCKET}/fullload/')sdf.printSchema()
Step 2. Then write delta table to s3
# write data as DELTA TABLEsdf.write.format("delta").mode("overwrite").save("s3://"+ BUCKET +"/delta/insurance/")
Step 3. Read update data from cdcload
# read cdc update datacdc_df = spark.read.csv(f's3://{BUCKET}/cdcload/')
Step 3. UPMERGE updates into the target
# read fullload to dataframe from existing delta tabledelta_df = DeltaTable.forPath(spark, "s3://"+ BUCKET +"/delta/insurance/")
and
final_df = delta_df.alias("prev_df").merge( \source = cdc_df.alias("append_df"), \#matching on primarykeycondition = expr("prev_df.policy_id = append_df._c1"))\.whenMatchedUpdate(set= {"prev_df.expiry_date" : col("append_df._c2"),"prev_df.location_name" : col("append_df._c3"),"prev_df.state_code" : col("append_df._c4"),"prev_df.region_name" : col("append_df._c5"),"prev_df.insured_value" : col("append_df._c6"),"prev_df.business_type" : col("append_df._c7"),"prev_df.earthquake_coverage" : col("append_df._c8"),"prev_df.flood_coverage" : col("append_df._c9")} )\.whenNotMatchedInsert(values =#inserting a new row to Delta table{ "prev_df.policy_id" : col("append_df._c1"),"prev_df.expiry_date" : col("append_df._c2"),"prev_df.location_name" : col("append_df._c3"),"prev_df.state_code" : col("append_df._c4"),"prev_df.region_name" : col("append_df._c5"),"prev_df.insured_value" : col("append_df._c6"),"prev_df.business_type" : col("append_df._c7"),"prev_df.earthquake_coverage" : col("append_df._c8"),"prev_df.flood_coverage" : col("append_df._c9")})\.execute()
Validate#
- Filter temporary dataframe
- Filter temporary table
Let create a temp dataframe from the delta table
# read target tabledelta_df = DeltaTable.forPath(spark, "s3://"+ BUCKET +"/delta/insurance/")temp_df = delta_df.toDF()
Filter on dataframe
temp_df.where("policy_id IN (100462, 100463, 100475)").show()
Create a temp table
temp_df.createOrReplaceTempView("temp_view")
Query filter on the temp table
spark.sql("SELECT * FROM temp_view WHERE policy_id IN (100462, 100463, 100475)").show()
Glue Job#
[!NOTE] After interactive develop using Glue notebook, we can create a Glue ETL job to do full load and cdc update.