
Introduction#
GitHub this note shows
- Create Athena Query, Spark workgroups
- Control access to Athena workgroup via IAM here
- Create an external table from Athena editor
- Create table by Glue Crawler then query with Athena
- Play with a Athena Spark notebook
It is noted that
- Data catalog is created by glue and seen by athena
- Query engine are athena or spark, but spark only avaiable in some regions
- Have to terminate Spark sessions before deleting workgroups
- Queries can be saved and load
- Notebook and be exported and imported
Athena WorkGroup#
Enum to select Athena query or PySpark
export enum AthenaAnalyticEngine {PySpark = 'PySpark engine version 3',Athena = 'Athena engine version 3'}
Create an Athena workgroup for SQL query
const workgroup = new CfnWorkGroup(this, 'WorkGroupDemo', {name: 'WorkGroupDemo',description: 'demo',// destroy stack can delete workgroup event not empyrecursiveDeleteOption: true,state: 'ENABLED',workGroupConfiguration: {bytesScannedCutoffPerQuery: 107374182400,engineVersion: {// pyspark not support in cloudformation// available in some regions at this momentselectedEngineVersion: AthenaAnalyticEngine.Athena},requesterPaysEnabled: true,publishCloudWatchMetricsEnabled: true,resultConfiguration: {// encryption defaultoutputLocation: `s3://${props.destS3BucketName}/`}}})
Create an Athena workgroup with PySpark
const sparkWorkGroup = new CfnWorkGroup(this, 'SparkWorkGroup', {name: sparkWorkGroupName,description: 'spark',recursiveDeleteOption: true,state: 'ENABLED',workGroupConfiguration: {executionRole: role.roleArn,bytesScannedCutoffPerQuery: 107374182400,engineVersion: {// effectiveEngineVersion: "",selectedEngineVersion: AthenaAnalyticEngine.PySpark},requesterPaysEnabled: true,publishCloudWatchMetricsEnabled: false,resultConfiguration: {outputLocation: `s3://${props.destS3BucketName}/`}}})
Create Table - Crawler#
- Example 1: amazon-review-pds/parquet
- Example 2: amazon-review-pds/tsv
It is quite straightfoward to create table using Glue Crawler
- Create an IAM role for Glue Crawler
- Create a Glue Crawler and specify the data source in S3
- After the crawler complete, you can query the table from Athena
Create Table - Parquet Data#
- Example 1: amazon-reviews-pds dataset (parquet with partitions), check data size
aws s3 ls --summarize --human-readable --recursive s3://amazon-reviews-pds/parquet/aws s3 ls --summarize --human-readable --recursive s3://gdelt-open-data/events/
Use the s3://amazon-reviews-pds/parquet to create a table and then query
create external table amazon_reviews_parquet_table (marketplace string,customer_id string,review_id string,product_id string,product_parent string,product_title string,star_rating int,helpful_votes int,total_votes int,vine string,verified_purchase string,review_headline string,review_body string,review_date date,`year` int)partitioned by (product_category string)row format serde 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'stored as inputformat 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat' outputformat 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'location "s3://amazon-reviews-pds/parquet/"tblproperties ("classification" = "parquet")
We have to update partitions by using MSCK
msck repair table amazon_reviews_parquet_table;
Or use the ALTER sql
ALTER TABLE mytable SET LOCATION 's3://amazon-reviews-pds/parquet/product_category=Gift_Card/';
Finally query the new created table
select marketplace, customer_id, review_id, star_rating, review_body from mytable limit 10;
Create Table - CSV Data#
As the amazon-reviews-pds tsv prefix container some noisy files such as index.txt, you need to exclude it while creating a new table in Athena. I work around this by copy tsv.gz data to my own S3 bucket first. Check data size
aws s3 ls --summarize --human-readable --recursive s3://amazon-reviews-pds/parquet/aws s3 ls --summarize --human-readable --recursive s3://gdelt-open-data/events/
aws s3 cp s3://amazon-reviews-pds/tsv/ s3://my-bucket/tsv/ --exclude '*' --include '*.tsv.gz' --recursive
Use the same amazon-reviews-pds but source the tsv data.
create external table amazon_reviews_tsv_table (marketplace string,customer_id string,review_id string,product_id string,product_parent string,product_title string,star_rating int,helpful_votes int,total_votes int,vine string,verified_purchase string,review_headline string,review_body string,review_date string,`year` int)row format delimited fields terminated by '\t' escaped by '\\' lines terminated by '\n'stored as inputformat 'org.apache.hadoop.mapred.TextInputFormat' outputformat 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'location "s3://amazon-reviews-pds/tsv/"tblproperties ("classification" = "csv","skip.header.line.count" = "1")
Or specifing serde and SERDEPROPERTIES as below
create external table tsvtest (marketplace string,customer_id string,review_id string,product_id string,product_parent string,product_title string,star_rating int,helpful_votes int,total_votes int,vine string,verified_purchase string,review_headline string,review_body string,review_date string,`year` int)row format serde 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'WITH SERDEPROPERTIES('field.delim' = '\t','escape.delim' = '\\','line.delim' = '\n')stored as inputformat 'org.apache.hadoop.mapred.TextInputFormat'outputformat 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'location "s3://athena-query-result-haimtran-us-east-1-08052023/tsv/"tblproperties ("classification"="csv", "skip.header.line.count"="1")
You might need to update partition and metadata using MSCK
msck repair table mytable;
Create Table - CTAS#
- Convert data from tsv to parquet
- CTAS means CREATE TABLE AS SELECT
- Create a new table, parquet format from result of a query, same location
- Create a new table, parquet format from result of a query, external location
First, create a new table in the same location bucket. The partition key should placed at the last. This takes about 5 minutes
create table if not exists ctas_tsv_to_parquet_table with (format = 'parquet') asselect "marketplace","customer_id","review_id","product_id","product_title","star_rating"from "amazon_reviews_tsv_table";
Second, create the new table in an external location. This takes about 5 minutes
create table if not exists ctas_tsv_to_parquet_partitioned_table with (format = 'parquet',partitioned_by = array [ 'marketplace' ]) asselect "customer_id","review_id","product_id","product_title","star_rating","marketplace"from "amazon_reviews_tsv_table"where marketplace in ('US', 'JP')
print columns
select *from information_schema.columnswhere table_name = 'amazon_reviews_parquet_table'
Insert Table#
- Insert select
- Insert values
First create a table using ctas from parquet table
create table if not exists ctas_table_partitioned with (format = 'parquet',partitioned_by = array [ 'marketplace' ]) asselect "customer_id","review_id","product_id","product_title","star_rating","marketplace"from "amazon_reviews_parquet_table"where marketplace in ('US', 'JP')
Check the current output
select count(*) from "ctas_table_partitioned"
Then insert data into the ctas_table by selecting from the parquet table
insert into "ctas_table_partitioned"select "customer_id","review_id","product_id","product_title","star_rating","marketplace"from "amazon_reviews_parquet_table"where marketplace in ('FR')
Check the output after inserting
select *from "ctas_table_partitioned"where marketplace = 'FR'
Let insert values into ctas_table
insert into "ctas_table"values('VN','12345678','12345678','12345678','TCB',5);
Let check the output
select "marketplace","customer_id"from "ctas_table"where marketplace = 'VN';
Parquet versus TSV#
Create the same query with two tables to see performance and cost. First, for the tsv table
select "customer_id",sum("star_rating") as sum_ratingfrom "amazon_reviews_csv_table"group by "customer_id"order by sum_rating desc
and for parquet table
select "customer_id",sum("star_rating") as sum_ratingfrom "amazon_reviews_parquet_table"group by "customer_id"order by sum_rating desc
- tsv: scanned 32.22 GB and runtime 97 seconds
- parquet: scanned 1.21 GB and runtime 38 seconds
- check time in queue
Compare the count row
select count(*) as num_row from "amazon_reviews_parquet_table"
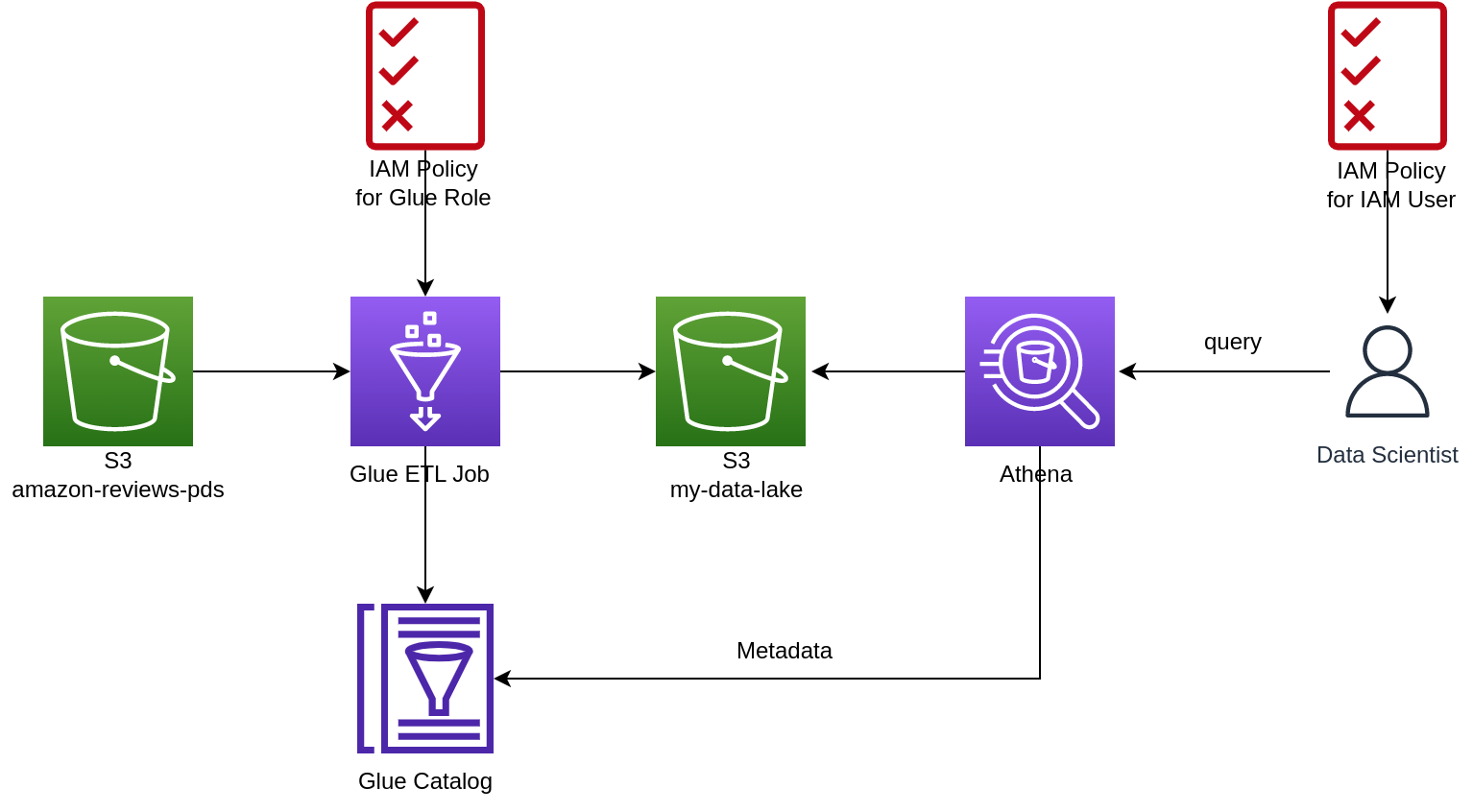
Data Scientist#
Before Lake Formation released in 2019, we need to configure data access via IAM Policy. For example, if there is Data Scientist (IAM user), to enable the DS to query tables in Glue Catalog, we need to configure
- S3 IAM policy to grant access the underlying data
- Glue IAM Policy to grant access database, table in Catalog
Create an IAM user
const secret = new aws_secretsmanager.Secret(this, `${props.userName}Secret`, {secretName: `${props.userName}Secret`,generateSecretString: {secretStringTemplate: JSON.stringify({ userName: props.userName }),generateStringKey: 'password'}})const user = new aws_iam.User(this, `${props.userName}IAMUSER`, {userName: props.userName,password: secret.secretValueFromJson('password'),passwordResetRequired: false})
Data Access via IAM#
Option 1. Grant the DS to access all data
user.addManagedPolicy(aws_iam.ManagedPolicy.fromAwsManagedPolicyName('AmazonAthenaFullAccess'))
Option 2. Least priviledge so the DS only can access requested tables. For Glue, please note that
All operations performed on a Data Catalog resource require permission on the resource and all the ancestors of that resource. For example, to create a partition for a table requires permission on the table, database, and catalog where the table is located. The following example shows the permission required to create partitions on table PrivateTable in database PrivateDatabase in the Data Catalog.
Specify the permission to access tables in Glue catalog
new aws_iam.PolicyStatement({actions: ["glue:CreateDatabase","glue:DeleteDatabase","glue:GetDatabase","glue:GetDatabases","glue:UpdateDatabase","glue:CreateTable","glue:DeleteTable","glue:BatchDeleteTable","glue:UpdateTable","glue:GetTable","glue:GetTables","glue:BatchCreatePartition","glue:CreatePartition","glue:DeletePartition","glue:BatchDeletePartition","glue:UpdatePartition","glue:GetPartition","glue:GetPartitions","glue:BatchGetPartition",],effect: Effect.ALLOW,resources: [`arn:aws:glue:${this.region}:*:table/${props.databaseName}/*`,`arn:aws:glue:${this.region}:*:database/${props.databaseName}*`,`arn:aws:glue:${this.region}:*:*catalog`,],}),
The full IAM policy attached to the DS IAM user
const policy = new aws_iam.Policy(this,"LeastPriviledgePolicyForDataScientist",{policyName: "LeastPriviledgePolicyForDataScientist",statements: [// athenanew aws_iam.PolicyStatement({actions: ["athena:*"],effect: Effect.ALLOW,// resources: ["*"],resources: [`arn:aws:athena:${this.region}:${this.account}:workgroup/${props.athenaWorkgroupName}`,],}),new aws_iam.PolicyStatement({actions: ["athena:ListEngineVersions","athena:ListWorkGroups","athena:GetWorkGroup","athena:ListDataCatalogs","athena:ListDatabases","athena:GetDatabase","athena:ListTableMetadata","athena:GetTableMetadata",],effect: Effect.ALLOW,resources: ["*"],}),// access s3new aws_iam.PolicyStatement({actions: ["s3:GetBucketLocation","s3:GetObject","s3:ListBucket","s3:ListBucketMultipartUploads","s3:ListMultipartUploadParts","s3:AbortMultipartUpload","s3:CreateBucket","s3:PutObject","s3:PutBucketPublicAccessBlock",],effect: Effect.ALLOW,resources: [props.athenaResultBucketArn,`${props.athenaResultBucketArn}/*`,props.sourceBucketArn,`${props.sourceBucketArn}/*`,],}),// access glue catalognew aws_iam.PolicyStatement({actions: ["glue:CreateDatabase","glue:DeleteDatabase","glue:GetDatabase","glue:GetDatabases","glue:UpdateDatabase","glue:CreateTable","glue:DeleteTable","glue:BatchDeleteTable","glue:UpdateTable","glue:GetTable","glue:GetTables","glue:BatchCreatePartition","glue:CreatePartition","glue:DeletePartition","glue:BatchDeletePartition","glue:UpdatePartition","glue:GetPartition","glue:GetPartitions","glue:BatchGetPartition",],effect: Effect.ALLOW,resources: [`arn:aws:glue:${this.region}:*:table/${props.databaseName}/*`,`arn:aws:glue:${this.region}:*:database/${props.databaseName}*`,`arn:aws:glue:${this.region}:*:*catalog`,],}),// access lakeformation// new aws_iam.PolicyStatement({// actions: ["lakeformation:GetDataAccess"],// effect: Effect.ALLOW,// resources: ["*"],// }),],}
IAM Role for Glue#
- Create an IAM Role for Glue
- Create a Glue Notebook or interactive session
- Read data from Glue catalog, S3
- AWSGlueServiceRoleNotebook name convention and iam:PassRole here
const role = new aws_iam.Role(this, `GlueRoleFor-${props.pipelineName}`, {roleName: `GlueRoleFor-${props.pipelineName}`,assumedBy: new aws_iam.ServicePrincipal('glue.amazonaws.com')})role.addManagedPolicy(aws_iam.ManagedPolicy.fromAwsManagedPolicyName('service-role/AWSGlueServiceRole'))role.addManagedPolicy(aws_iam.ManagedPolicy.fromAwsManagedPolicyName('CloudWatchAgentServerPolicy'))
Then attach the same policy bove LeastPriviledgePolicyForDataScientist to the Gule role. The notebook need to pass role to the execution session, so there are to options
- Explicit sepcify iam:PassRole in the policy below
- Follow the role name convetion such as AWSGlueServiceRoleNotebook
const policy = new aws_iam.Policy(this,'LeastPriviledgePolicyForGlueNotebookRole',{policyName: 'LeastPriviledgePolicyForGlueNotebookRole',statements: [// pass iam rolenew aws_iam.PolicyStatement({actions: ['iam:PassRole', 'iam:GetRole'],effect: Effect.ALLOW,resources: ['*']}),// athenanew aws_iam.PolicyStatement({actions: ['athena:*'],effect: Effect.ALLOW,resources: ['*']}),// access s3new aws_iam.PolicyStatement({actions: ['s3:*'],effect: Effect.ALLOW,resources: [props.athenaResultBucketArn,`${props.athenaResultBucketArn}/*`,props.sourceBucketArn,`${props.sourceBucketArn}/*`]}),// access glue catalognew aws_iam.PolicyStatement({actions: ['glue:*'],effect: Effect.ALLOW,resources: [`arn:aws:glue:${this.region}:*:table/${props.databaseName}/*`,`arn:aws:glue:${this.region}:*:database/${props.databaseName}*`,`arn:aws:glue:${this.region}:*:*catalog`]})]})
policy.attachToUser(user)
Athena Spark Notebook#
Troubleshooting#
- check s3 bucket size
- data with null value
- delimeter comman or tab
- format such as parquet, csv
some slow queries
select customer_id, product_id, sum(star_rating) as sum_rating from parquetgroup by customer_id, product_idorder by sum_rating desc;
Check s3 data size
aws s3 ls --summarize --human-readable --recursive s3://amazon-reviews-pds/parquet/aws s3 ls --summarize --human-readable --recursive s3://gdelt-open-data/events/
Useful vim command to insert comma to end of each column line name
:%/s/$/,/g