
Introduction#
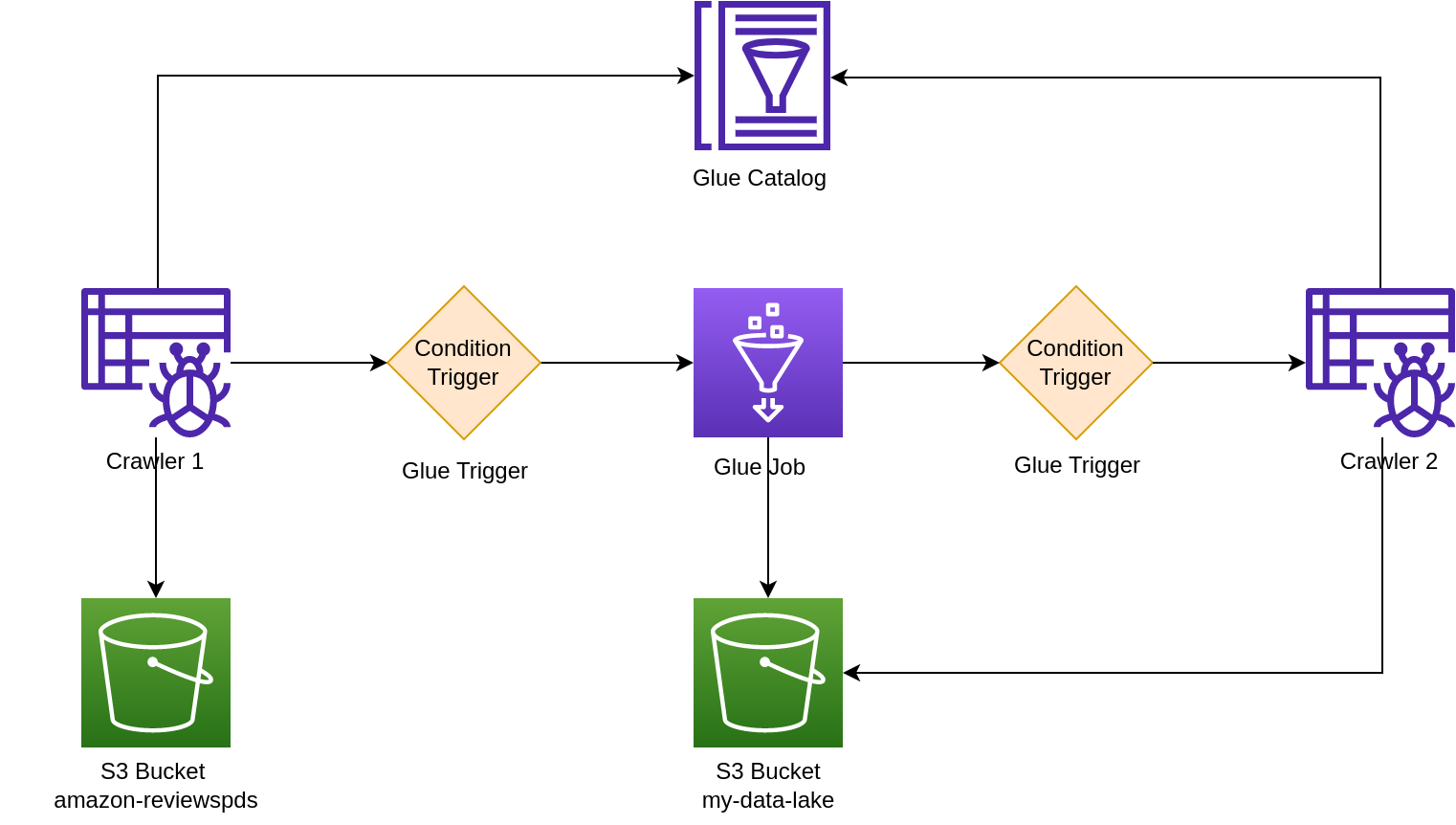
GitHub This note shows a simple workflow using Glue. There are some basic concepts
- workflow is a container of multiple glue job
- glue job running your code on (container) data processing unit (DPU) or worker type
- there are different job type such as pythonshell, spark (glueetl)
- trigger to kick start a job
- starting trigger (on per workflow) to start a workflow
- trigger has mutliple type: ON_DEMAND, CRON, CONDITIONAL
- glue job bookmark
Prepare ETL Code#
In CDK, we can use s3 asset to upload our ETL processing code a s3 bucket, then glue job will take these code to run on worker (DPU, G1.X, G2.X)
const pyScriptPath = new Asset(this, 'py-glue-demo', {path: path.join(__dirname, './../script/python_demo.py')})const sparkScriptPath = new Asset(this, 'spark-script-demo', {path: path.join(__dirname, './../script/read_amazon_reviews_tsv.py')})
Role for Glue#
Glue job need to access s3 for code, and save results to destination bucket. In case of creating tables in a lake registered to Lake Formation, then Lake Formation need to grant data location permissions to the Glue role.
const jobRole = new cdk.aws_iam.Role(this, 'RoleForGlueJobDemo', {roleName: 'AWSGlueServiceRole-Demo',assumedBy: new cdk.aws_iam.ServicePrincipal('glue.amazonaws.com')})jobRole.addManagedPolicy(cdk.aws_iam.ManagedPolicy.fromManagedPolicyArn(this,'AWSGlueServicePolicy','arn:aws:iam::aws:policy/service-role/AWSGlueServiceRole'))jobRole.addToPolicy(new cdk.aws_iam.PolicyStatement({effect: Effect.ALLOW,actions: ['logs:*'],resources: ['*']}))jobRole.addToPolicy(new cdk.aws_iam.PolicyStatement({effect: Effect.ALLOW,actions: ['s3:*'],resources: ['*']}))jobRole.addToPolicy(new cdk.aws_iam.PolicyStatement({effect: Effect.ALLOW,actions: ['lakeformation:GetDataAccess'],resources: ['*']}))jobRole.addToPolicy(new cdk.aws_iam.PolicyStatement({effect: Effect.ALLOW,actions: ['iam:PassRole'],resources: ['*']}))
Pythonshell Job#
Python shell job run with either 0.0625 DPU or 1 DPU (4vCPU and 16GB RAM), this is not running in a Spark cluster. These jobs have a 1-minute minimum billing duration. Compatible python versions are 2.7, 3.6 and 3.9, please check supported libs here
const pythonJob = new CfnJob(this, 'SimpleJob', {name: 'SimpleJobTest',command: {name: 'pythonshell',pythonVersion: '3.9',scriptLocation: pyScriptPath.s3ObjectUrl},defaultArguments: {'--name': ''},role: jobRole.roleArn,executionProperty: {maxConcurrentRuns: 1},maxRetries: 2,timeout: 60,maxCapacity: 1})
Spark Job#
This job can run in multiple DPU or worker type (G1.X, 4vCPUs, 16GB) (G2.X, 8vCPUs, 32GB), (G.025X, 2 vCPUs, 4GB), and (Starndard, 4vCPUs, 16GB). The command name should be glueetl and should check the glueVersion for spark and python version supported. By default, AWS Glue allocates 10 DPUs to each spark job and 2 DPUs to each spark streaming job. Job using AWS Glue version 0.9 or 1.0 have a 10-minute minimum billing duration, while jobs that use AWS Glue version 2.0 and later have 1-minute minimum. detail
const sparkJob = new CfnJob(this, 'WorflowDemo-Read-S3', {name: 'WorkFlowDemo-Read-S3',command: {name: 'glueetl',pythonVersion: '3',scriptLocation: sparkScriptPath.s3ObjectUrl},defaultArguments: {'--source_data_path': props.sourceDataPath,'--dest_data_path': props.destDataPath},role: jobRole.roleArn,executionProperty: {maxConcurrentRuns: 1},// spark jobglueVersion: '3.0',maxRetries: 1,timeout: 1200,// spark etl job can have more than 2 dpu// use dpu then do not user worker type// maxCapacity: 6,numberOfWorkers: 5,workerType: 'G.1X'})
Glue Crawler#
- Setup classifider to skip header in csv
- Lake Formation grant data location for creating catalog tables
Ceate a csv classifier
const classifier = new CfnClassifier(this, 'Classifier-GlueWorkFlow-S3-Stack', {csvClassifier: {name: classifierName,containsHeader: 'PRESENT',delimiter: ',',header: ['marketplace','customer_id','review_id','product_id','product_parent','product_title','product_category','star_rating','helpful_votes','total_votes','vine','verified_purchase','review_headline','review_body','review_date'],quoteSymbol: '"'}})
Then create a crawler which crawl tsv and create a catalog table
const crawler = new CfnCrawler(this, `Crawler-GlueWorkFlowDemo-S3-Stack`, {name: 'Crawler-GlueWorkFlowDemo-S3-Stack',role: jobRole.roleArn,targets: {s3Targets: [{path: props.destDataPath,sampleSize: 1}]},databaseName: 'default',description: 'craw transformed data',tablePrefix: props.tableName,classifiers: [(classifier.csvClassifier as CfnClassifier.CsvClassifierProperty).name!]})
Glue Trigger#
Trigger should lives in a workflow, to let create a workflow first.
const workflow = new CfnWorkflow(this, 'WorkFlowDemo-S3-Stack', {name: 'WorflowDemo-S3-Stack',description: 'demo workflow'})
There is only one starting trigger for a workflow, detail
const triggerPythonJob = new CfnTrigger(this, 'TriggerPythonJob-S3-Stack', {name: 'TriggerPythonJob-S3-Stack',description: 'trigger the simple job',actions: [{jobName: pythonJob.name,timeout: 300},{jobName: sparkJob.name,timeout: 300}],workflowName: workflow.name,type: 'ON_DEMAND'})
Then jobs can be chain using tringger (conditional). Please note that you have to activate the trigger or setting startOnCreation to true.
const conditionTrigger = new CfnTrigger(this, 'ConditionTrigger-S3-Stack', {name: 'ConditionTrigger-S3-Stack',description: 'when both jobs done trigger this',startOnCreation: true,actions: [{crawlerName: crawler.name,timeout: 600}],workflowName: workflow.name,type: 'CONDITIONAL',predicate: {conditions: [{logicalOperator: 'EQUALS',state: 'SUCCEEDED',jobName: sparkJob.name},{logicalOperator: 'EQUALS',state: 'SUCCEEDED',jobName: pythonJob.name}],logical: 'AND'}})
Job Bookmark#
It track information states of job and prevent duplicatte processing data which already processed
- S3 and object timestamp
- RDS and bookmark key column which keep increasing
Let create a bookmark job stack
new aws_glue.CfnJob(this, "GlueJobBookMarkDemo", {name: "GlueJobBookMarkDemo1",command: {name: "glueetl",pythonVersion: "3",scriptLocation: sparkScriptPath.s3ObjectUrl,},defaultArguments: {"--source_data_path": props.sourceDataPath,"--dest_data_path": props.destDataPath,"--job-bookmark-option": JobBookMarkOption.ENABLE,"--enable-auto-scaling": true,},role: role.roleArn,executionProperty: {maxConcurrentRuns: 1,},glueVersion: "3.0",maxRetries: 0,timeout: 1200,// enable autosclaing this is max_num_workernumberOfWorkers: 5,workerType: "G.1X",});
Let create a simple ETL pysparck script which download data from a S3, transform and write to another S3
# parse argumentsargs = getResolvedOptions(sys.argv, ["JOB_NAME", "source_data_path", "dest_data_path"])# job bookmark enablejob = Job(glueContext)job.init(args['JOB_NAME'], args)# read data from sourcedf_glue = glueContext.create_dynamic_frame.from_options(format_options={"quoteChar": '"',"withHeader": True,"separator": "\t",},connection_type="s3",format="csv",connection_options={"paths": [args["source_data_path"]],"recurse": True,},transformation_ctx="df_glue",)# transformdf_clean = xxx# write data to destinationglueContext.write_dynamic_frame.from_options(frame=df_glue_clean,connection_type="s3",format="glueparquet",connection_options={"path": args["dest_data_path"],},format_options={"compression": "uncompressed"},transformation_ctx="S3bucket_node3",)# job bookmark commitjob.commit()
To check how it works, upload a csv file to source
aws s3 cp xxx s3://bucket-name/source-csv/001.tsv.gz
Run the Glue job and check the output
aws s3 ls s3://bucket-name/job-bookmark/
Run the job again, and validate that no new data created in output
aws s3 ls s3://bucket-name/job-bookmark/
Upload another file to source and run the job again
aws s3 cp xxx s3://bucket-name/source-csv/002.tsv.gz
Check output and validate that only one new file created in the output
aws s3 ls s3://bucket-name/job-bookmark/