
Introduction#
This GitHub shows some basic serverless architecture with kinesis
- kinesis firehose and dynamic partition
- lambda and kinesis enhanced fan-out
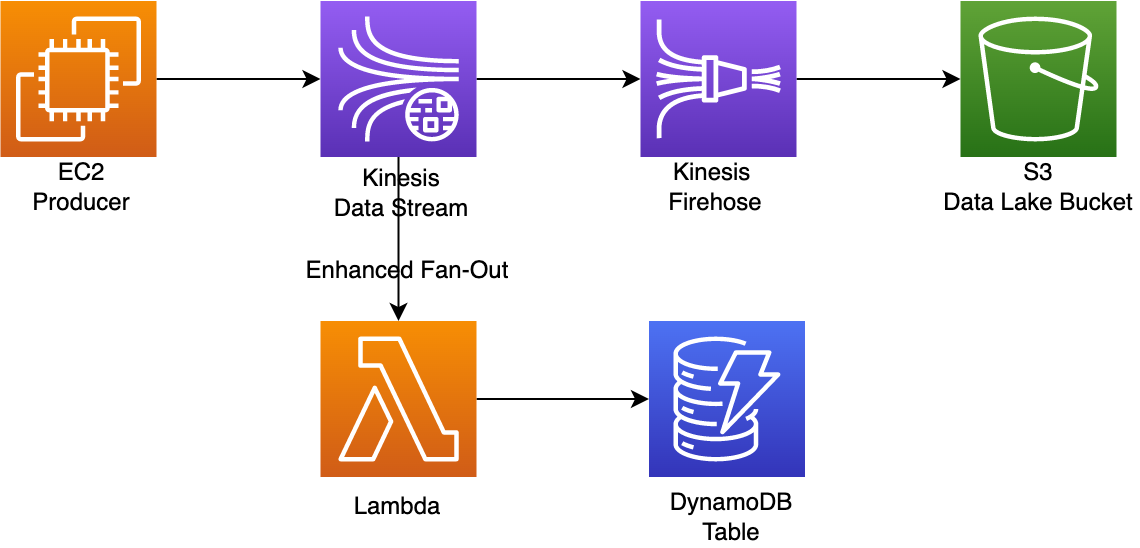
Kinesis Firehose#
Let create a Kinesis Frehose to deliver data from Kinesis Data Stream to S3. First, we need a role for Firehose to access the stream source, and write data to S3.
// role for kinesis firehoseconst role = new aws_iam.Role(this, 'RoleForKinesisFirehose', {assumedBy: new aws_iam.ServicePrincipal('firehose.amazonaws.com'),roleName: 'RoleForKinesisFirehose'})role.addToPolicy(new aws_iam.PolicyStatement({effect: Effect.ALLOW,actions: ['s3:*'],resources: ['*']}))role.addToPolicy(new aws_iam.PolicyStatement({effect: Effect.ALLOW,actions: ['cloudwatch:*'],resources: ['*']}))role.addToPolicy(new aws_iam.PolicyStatement({effect: Effect.ALLOW,actions: ['logs:*'],resources: ['*']}))const firehorsePolicy = new aws_iam.Policy(this, 'FirehosePolicy', {roles: [role],statements: [new aws_iam.PolicyStatement({effect: Effect.ALLOW,actions: ['kinesis:*'],resources: ['*']})]})
Next, create a delivery stream with Kinesis Firehose
// create a firehorse deliveryconst firehose = new aws_kinesisfirehose.CfnDeliveryStream(this,'KinesisFirehoseDemo',{deliveryStreamName: 'KinesisFirehoseDemo',// direct put or kinesis as sourcedeliveryStreamType: 'KinesisStreamAsSource',kinesisStreamSourceConfiguration: {// source streamkinesisStreamArn: `arn:aws:kinesis:${this.region}:${this.account}:stream/${props.streamName}`,// role access sourceroleArn: role.roleArn},s3DestinationConfiguration: {bucketArn: `arn:aws:s3:::${props.bucketName}`,// role access destinationroleArn: role.roleArn,bufferingHints: {intervalInSeconds: 60,sizeInMBs: 123},cloudWatchLoggingOptions: {enabled: true,logGroupName: 'FirehoseDemo',logStreamName: 'FirehoseDemo'},// compressionFormat: "",// encryptionConfiguration: {},errorOutputPrefix: 'firehose-error',prefix: 'firehose-data'}})
Need to add some dependencies
firehose.addDependency(role.node.defaultChild as CfnResource)firehose.addDependency(firehorsePolicy.node.defaultChild as CfnResource)
Lamda and Kinesis#
create a role for lambda function
// role for lambdaconst roleLambda = new aws_iam.Role(this, 'RoleForLambdaConsumerKinesis', {roleName: 'RoleForLambdaConsumerKinesis',assumedBy: new aws_iam.ServicePrincipal('lambda.amazonaws.com')})// attach an aws managed policy allow accessing cw logsroleLambda.addManagedPolicy(aws_iam.ManagedPolicy.fromAwsManagedPolicyName('service-role/AWSLambdaBasicExecutionRole'))// cloudwatch log policy accessing kinesis and ddbroleLambda.attachInlinePolicy(new aws_iam.Policy(this, 'ReadKinesisStream', {statements: [new aws_iam.PolicyStatement({effect: Effect.ALLOW,actions: ['kinesis:*'],resources: ['*']}),new aws_iam.PolicyStatement({effect: Effect.ALLOW,actions: ['dynamodb:*'],resources: ['*']})]}))
create a lambda function
const func = new aws_lambda.Function(this, 'LambdaConsumerKinesisStream', {functionName: 'LambdaConsumerKinesisStream',code: aws_lambda.Code.fromInline(fs.readFileSync(path.resolve(__dirname, './../lambda/index.py'), {encoding: 'utf-8'})),handler: 'index.handler',runtime: aws_lambda.Runtime.PYTHON_3_8,timeout: Duration.seconds(10),memorySize: 512,role: roleLambda,environment: {TABLE_NAME: props.tableName,STREAM_NAME: props.streamName}})
create a dynamod db table
// dynamodb tableconst table = new aws_dynamodb.Table(this, 'StockTable', {tableName: props.tableName,removalPolicy: RemovalPolicy.DESTROY,partitionKey: {name: 'id',type: aws_dynamodb.AttributeType.STRING},billingMode: aws_dynamodb.BillingMode.PAY_PER_REQUEST,stream: aws_dynamodb.StreamViewType.NEW_IMAGE})
create a kinesis data stream
const stream = new aws_kinesis.Stream(this, `${props.streamName}-demo`, {streamName: props.streamName,retentionPeriod: Duration.hours(24),shardCount: 4,streamMode: aws_kinesis.StreamMode.PROVISIONED})
register a consumer with kinesis enhanced fan-out
const consumer = new aws_kinesis.CfnStreamConsumer(this,'LambdaRegisterConsumer',{consumerName: 'LambdaRegisterConsumer',streamArn: stream.streamArn})
configure lambda envent source mapping to processing messages in kinesis data stream
const eventSource = new aws_lambda.EventSourceMapping(this,'LambdaEventSourceMappingKinesis',{target: func,eventSourceArn: consumer.attrConsumerArn,batchSize: 10,parallelizationFactor: 2,// maxConcurrency: 5,// maxRecordAge: Duration.minutes(30),startingPosition: aws_lambda.StartingPosition.LATEST,// tumblingWindow: Duration.minutes(1),enabled: true,retryAttempts: 1})
Lambda Handler#
the handler receive event from kinesis then parse records and write to ddb
# haimtran 03 DEC 2022# receive event from kinesis data stream# lambda write messages to dyanmdodbimport osimport datetimeimport uuidimport jsonimport boto3# create dynamodb clientddb = boto3.resource("dynamodb")table = ddb.Table(os.environ["TABLE_NAME"])def handler(event, context) -> json:"""simple lambda function"""# time stampnow = datetime.datetime.now()time_stamp = now.strftime("%Y/%m/%d %H:%M:%S.%f")# parse message from post request bodyrecords =[]try:records = event["Records"]except:print("error parsing message from post body")# write record to dynamodbfor record in records:try:table.put_item(Item={"id": str(uuid.uuid4()), "message": str(record)})except:table.put_item(Item={"id": str(uuid.uuid4()), "message": "NULL"})return {"statusCode": 200,"headers": {"Access-Control-Allow-Origin": "*","Access-Control-Allow-Headers": "Content-Type","Access-Control-Allow-Methods": "OPTIONS,GET",},"body": json.dumps({"time": f"lambda {time_stamp}", "event": event}),}
Simple Producer#
let put some messages to the stream and see results in dynamod db
import datetimeimport jsonimport randomimport boto3import timeSTREAM_NAME = "sensor-input-stream"REGION = "ap-southeast-1"def get_random_data():current_temperature = round(10 + random.random() * 170, 2)if current_temperature > 160:status = "ERROR"elif current_temperature > 140 or random.randrange(1, 100) > 80:status = random.choice(["WARNING","ERROR"])else:status = "OK"return {'sensor_id': random.randrange(1, 100),'current_temperature': current_temperature,'status': status,'event_time': datetime.datetime.now().isoformat()}def send_data(stream_name, kinesis_client):while True:data = get_random_data()partition_key = str(data["sensor_id"])print(data)kinesis_client.put_record(StreamName=stream_name,Data=json.dumps(data),PartitionKey=partition_key)#time.sleep(2)if __name__ == '__main__':kinesis_client = boto3.client('kinesis', region_name=REGION)send_data(STREAM_NAME, kinesis_client)
Troubleshooting#
Configure the ParallelizationFactor setting to process one shard of a Kinesis or DynamoDB data stream with more than one Lambda invocation simultaneously. You can specify the number of concurrent batches that Lambda polls from a shard via a parallelization factor from 1 (default) to 10. For example, when you set ParallelizationFactor to 2, you can have 200 concurrent Lambda invocations at maximum to process 100 Kinesis data shards. This helps scale up the processing throughput when the data volume is volatile and the IteratorAge is high. Note that parallelization factor will not work if you are using Kinesis aggregation. For more information, see New AWS Lambda scaling controls for Kinesis and DynamoDB event sources. Also, see the Serverless Data Processing on AWS workshop for complete tutorials.