
Setup#
- Create a collection with vector enabled
- Create an index
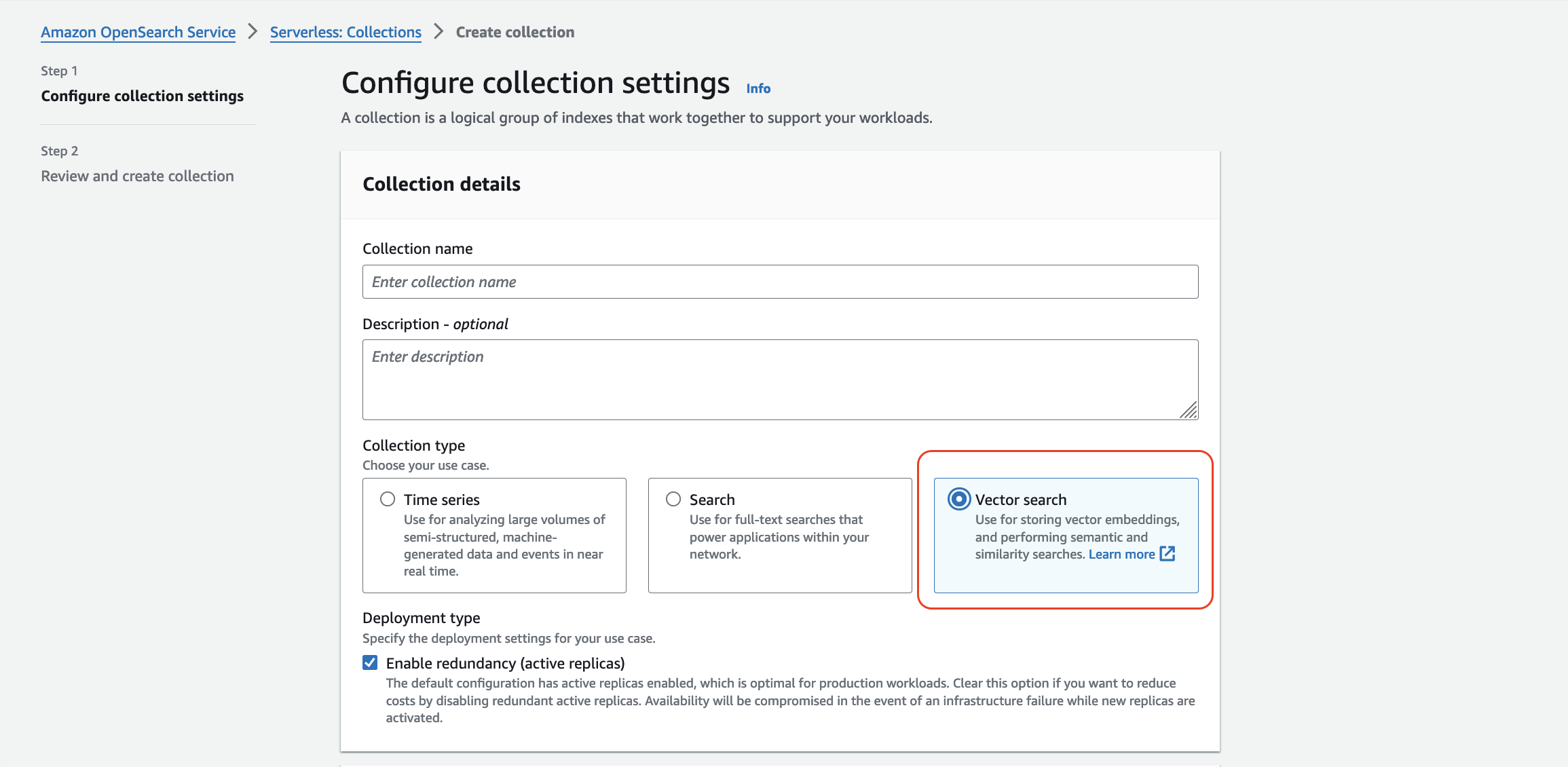
Let create a collection
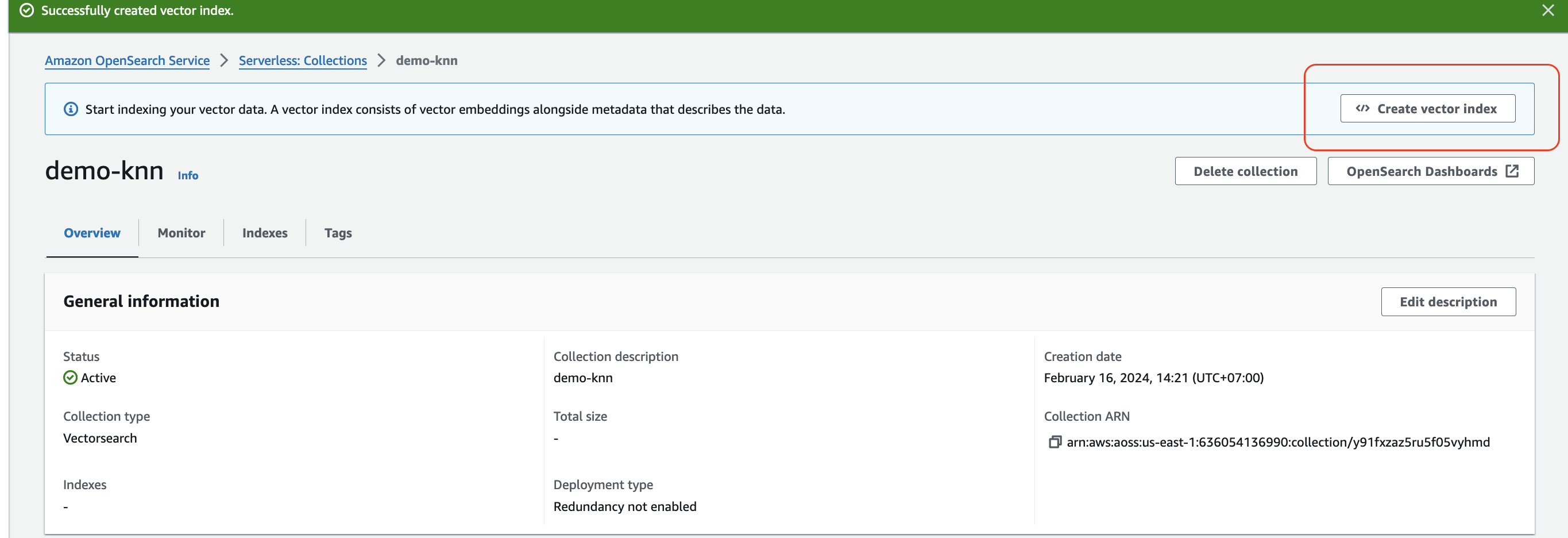
Then create a index
Then install dependencies, here is requirements.txt
boto3==1.26.25boto3-stubs==1.24.26botocore==1.29.25botocore-stubs==1.27.42.post1requests-aws4auth==1.1.2opensearch-py==2.0.0
Client#
Let creat a opensearch client which using oass service
from opensearchpy import OpenSearch, RequestsHttpConnectionfrom requests_aws4auth import AWS4Authimport boto3service = 'aoss'region = 'us-east-1'credentials = boto3.Session().get_credentials()# authenticationawsauth = AWS4Auth(credentials.access_key,credentials.secret_key,region,service,session_token=credentials.token,)# oass clientclient = OpenSearch(hosts=[{"host": os.environ['OASS_URL'], "port": 443}],http_auth=awsauth,use_ssl=True,verify_certs=True,connection_class=RequestsHttpConnection,timeout=300,)
Please note OASS_URL does not conttain https
Operations#
Let create a index which support KNN
# create index with vector supportclient.indices.create(index='demo',body={"settings": {"index.knn": True},"mappings": {"properties": {"housing-vector": {"type": "knn_vector","dimension": 3072},"title": {"type": "text"},"price": {"type": "long"},"location": {"type": "geo_point"}}}})
Let index a simple data
# index dataclient.index(index='demo',body={"housing-vector": e1,"title": "2 bedroom in downtown Seattle","price": "2800","location": "47.71, 122.00"})
Then query data
# query indexclient.search(index='demo',body={"size": 5,"query": {"knn": {"housing-vector": {"vector": e1,"k": 5}}}})
List Documents#
Let list all documents
# list all documentresponse = client.search(index="demo",body={"size": 15,"query": {"match_all": {}}})ids = [hit["_id"] for hit in response["hits"]["hits"]]
Delete all documents
for id in ids:client.delete(index="demo",id=id)
Get an document by id
client.get(index='demo',id='1%3A0%3AZa2hDo4BqbiA4twioVwz')
LangChain#
Let integrate with LangChain. Basically, it pipe user prompt => vector database => prompt model => response.
docsearch = OpenSearchVectorSearch(embedding_function=embeddings,opensearch_url=f"https://{os.environ['OASS_URL']}",http_auth=awsauth,timeout=300,use_ssl=True,verify_certs=True,connection_class=RequestsHttpConnection,index_name='demo',engine='nmslib')
Then search on the existing document
docsearch.similarity_search(query='housing',vector_field='housing-vector',text_field='title',k=5)
Search by vector
docsearch.similarity_search_by_vector(embedding=e1,k=5)
Embedding#
Let use OpenAIEmbeddings to create sample embedding vectors.
First load OpenAI token
import osfrom dotenv import load_dotenvload_dotenv(".demo.env")
Then create a embedding model
from langchain.text_splitter import CharacterTextSplitterfrom langchain_community.vectorstores import OpenSearchVectorSearchfrom langchain_openai import OpenAIEmbeddings# load txtfrom langchain_community.document_loaders import TextLoaderloader = TextLoader("state_of_the_union.txt")documents = loader.load()text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)docs = text_splitter.split_documents(documents)# create fist embedding vectore1 = embeddings.embed_query(docs[0].page_content)
Here is the sample data state_of_the_union.txt